
Базы
данных
Одной из важных
возможностей ЭВМ является хранение и
обработка больших объемов информации,
причем происходит накопление не только
текстовых и
графических документов (рисунки, чертежи,
фотографии, географические
карты), но и страниц глобальной сети
HTML,
звуковых и видеофайлов.
Эти возможности реализуются с помощью
баз данных.
База данных
(БД) —
совокупность данных, организованных
по определенным правилам, предусматривающим
общие принципы описания, хранения и
манипулирования данными, которые
относятся к определенной предметной
области.
Под данными
понимается
информация, представленная в виде,
пригодном для обработки автоматическими
средствами при возможном участии
человека.
Под предметной
областью понимается
однородная часть реального мира,
которая представляет интерес для
конкретного исследования.
В качестве примера
простейших БД можно назвать телефонный
справочник,
расписание движения поездов, сведения
о сотрудниках предприятия, список
цен на товары, алфавитный или предметный
каталог книг в библиотеке, словарь
иностранных слов, результаты сдачи
сессии студентами, каталог
видеозаписей, список кулинарных рецептов,
каталог товаров (прайслист).
Главное достоинство
электронных БД— возможность быстрого
поиска и
отбора информации, а также простая
генерация (создание) отчета по заданной
форме. Например, по номерам зачеток
легко определить фамилии студентов
или по фамилии писателя составить список
его произведений.
Пользователей баз данных можно разделить
на три категории: конечные пользователи
(те, кто вводят, извлекают и используют
данные), программисты и системные
аналитики (те, кто пишут прикладные
программы обработки данных, определяют
логическую структуру БД) и администраторы.
Администратор
базы данных
— это лицо, отвечающее за выработку
требований к
базе данных во время ее проектирования,
реализацию БД в процессе
создания, эффективное использование и
сопровождение БД в процессе
эксплуатации. Администратор взаимодействует
с конечными пользователями
и программистами в процессе проектирования
БД, контролирует ее работоспособность,
отвечает за реорганизацию и своевременное
обновление информации, удаление
устаревших данных и за восстановление
разрушенных данных,
за обеспечение безопасности и целостности
данных.
Под безопасностью
данных понимают
защиту данных от случайного или
преднамеренного несанкционированного
доступа к ним лиц, не имеющих на это
права.
Под целостностью
понимается
возможность восстановления данных в
случае возникновения сбоев в работе.
Если БД содержит данные, используемые
многими пользователями, то очень важно,
чтобы данные и связи между ними не
разрушались.
Программисты и
системные аналитики, создавая
БД, стремятся упорядочить
информацию по различным признакам
(реквизитам, атрибутам), для
того чтобы можно было извлекать из БД
информацию с произвольным сочетанием
признаков.
В современной
технологии использования баз данных
предполагается, что
создание базы данных, ее поддержка и
обеспечение доступа пользователей
к ней осуществляется с помощью специального
программного обеспечения — систем
управления базами данных.
Системы управления
базами данных (СУБД)—
пакет программ, обеспечивающих
создание БД и организацию данных. СУБД
позволяют вводить,
отбирать и редактировать данные. СУБД
предоставляют средства для извлечения
данных по определенному критерию
(требованию, правилу). СУБД дают
возможность конечным пользователям
осуществлять непосредственное управление
данными, а программистам и системным
аналитикам быстро разрабатывать более
совершенные программные средства их
обработки.
Рассмотрим существующие классификации
баз данных.
По технологии
обработки данных БД подразделяются на
централизованные и распределенные.
Централизованная
БД хранится
в памяти одной ЭВМ.
Распределенная
БД состоит
из нескольких частей (возможно,
пересекающихся или даже дублирующих
друг друга), хранящихся на различных
ЭВМ вычислительной сети.
По способу установления
связей между данными различают
реляционные, иерархические и сетевые
БД.
Реляционная БД
является простейшей и наиболее привычной
формой представления
данных в виде таблицы. В теории множеств
таблице соответствует
термин отношение (relation),
который и дал название этой БД. Для нее
имеется развитый
математический аппарат— реляционное
исчисление и реляционная алгебра, где
определены такие математические
операции, как объединение, вычитание,
пересечение, соединение и др.
Существенный вклад
в разработку БД этого типа сделал
американский ученый Е. Кодд (Е.
Codd).
Достоинством
реляционной БД является сравнительная
простота инструментальных
средств ее поддержки, недостатком —
жесткость структуры данных
(невозможность, например, задания строк
таблицы произвольной
длины) и зависимость
скорости ее работы от размера базы
данных. Для многих
операций, определенных в такой БД, может
оказаться необходимым просмотр
всей БД.
Иерархическая и
сетевая БД
предполагают наличие связей между
данными, имеющими какой-либо общий
признак. В иерархической БД такие связи
могут быть отражены в виде дерева-графа,
где возможны только односторонние
связи от старших вершин к младшим. Это
ускоряет доступ к необходимой
информации, но только если все возможные
запросы отражены в структуре дерева.
Никакие иные запросы на извлечение
информации не будут удовлетворены.
Указанный недостаток
снят в сетевой БД, в которой (по крайней
мере, теоретически) возможны связи
«всех со всеми». Поскольку на практике
это осуществить
невозможно, приходится прибегать к
некоторым ограничениям. Использование
иерархической и сетевой БД ускоряет
доступ к информации в базе
данных. Каждый элемент данных должен
содержать ссылки на некоторые
другие элементы. По этой причине требуются
значительные ресурсы как дисковой,
так и оперативной памяти ЭВМ.
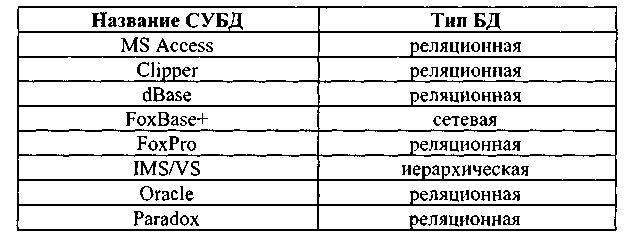
Сведения о некоторых СУБД приведены в
таблице.
Рассмотрим основные
понятия и компоненты реляционных БД
(например, MS
Access),
которые в настоящее время имеют наибольшее
коммерческое использование.
Реляционная БД
ориентирована на организацию данных в
виде двумерных
таблиц-отношений.
Каждая таблица
представляет собой двумерный массив
и обладает следующими свойствами:
-
каждый элемент таблицы — это один
элемент данных;
все столбцы в таблице однородные, т. е.
все элементы в столбце имеют
одинаковые длину и тип (числовой,
символьный и т. д.);
-
каждый столбец имеет уникальное имя;
-
одинаковые строки в таблице отсутствуют;
-
порядок следования строк и столбцов
может быть произвольным.
Таблица — это набор данных по
конкретной теме (предметной области),
например, сведения о студентах высшего
учебного заведения. Данные в таблице
располагаются в столбцах (полях)
и строках
(записях).
Поле—
это элементарная единица логической
организации данных, которая соответствует
отдельной, неделимой единице информации
— атрибуту.
Каждому полю
дается имя поля (идентификатор поля
внутри записи), например «Фамилия».
Запись —
это совокупность логически связанных
полей.
В реляционном
подходе к построению баз данных
используется терминология теории
отношений. Столбец таблицы со значениями
соответствующего
атрибута называется доменом,
а строка со
значениями разных атрибутов —
кортежем.
Итак, для реляционных БД существует
несколько равноправных терминов: столбец
может называться полем или доменом, а
строка — записью или кортежем.
На рисунке приведены две таблицы из
одной базы данных. Одна таблица содержит
основные сведения о студентах, вторая
— результаты сдачи сессии. Из рисунка
видно, что каждое поле имеет уникальное
(единственное в данной таблице) имя. В
таблице «Сессия» атрибут «Результат»
показывает средний бал, полученный при
сдаче сессии.
Каждая запись должна однозначно
идентифицироваться (определяться)
уникальным ключом записи. В общем
случае ключи записи бывают двух видов:
первичный (уникальный) и вторичный.
Первичный ключ —
это одно или несколько полей, однозначно
идентифицирующих запись. Если
первичный ключ состоит из одного поля,
он называется
простым, если
из нескольких полей — составным
ключом.
В приведенных выше
таблицах простым первичным ключом
является атрибут «Зачетка». В первой
таблице можно было попытаться использовать
в качестве простого первичного ключа
атрибут «Фамилия». Однако не исключена
возможность существования однофамильцев
среди студентов. В этом случае атрибут
«Фамилия» не сможет играть роль ключа,
однозначно определяющего каждую
запись. В качестве ключей часто используют
инвентарные,
табельные номера, электронные адреса,
номера ICQ,
паспортные номера и серии или просто
порядковые номера записей.
Вторичный ключ —
это такое поле, значение которого может
повторяться в нескольких записях, т. е.
он не является уникальным. Если по
значению первичного ключа может
быть найден один-единственный экземпляр
записи, то по вторичному ключу — несколько
записей.
Одной из основных
характеристик БД является набор
допустимых типов
данных, которые могут содержаться в
полях записей. За каждым полем записи
строго закреплен конкретный тип данных,
определяющий ограниченный
набор применимых к нему операций. К
типам данных относятся: символьный
(текстовый), числовой, булевский
(логический), денежный, дата, время,
связанный по технологии OLE
объект.
В реляционной БД
содержится, как правило, несколько
таблиц с различными сведениями.
Разработчик БД устанавливает связи
между отдельными
таблицами. При создании связей используют
ключевые поля. После установления связей
появляется возможность создания
запросов, форм и отчетов,
в которые помещаются данные из нескольких
связанных между собой таблиц.
Предположим, что в
рассматриваемой базе данных имеется
еще одна таблица с названием
«Стипендия», с помощью которой начисляется
стипендия в
зависимости от среднего балла за сессию
(в процентах от
максимальной стипендии). Ключевым полем
в этой таблице является столбец
с названием «Код».
Следующий рисунок
иллюстрирует
процесс создания связей между этими
тремя таблицами.

Для отбора данных
из БД, удовлетворяющих определенным
условиям, создается
запрос. Запрос
— это инструкция
для отбора нужных сведений из данной
БД в соответствии с определенными
условиями, которые порой называют
критериями.
Большинство СУБД
разрешают использовать запросы следующих
типов:
-
запрос-выборка,
предназначенный
для отбора данных, хранящихся
в таблицах, причем этот вид запроса не
изменяет эти данные; -
запрос-изменение, предназначенный
для перемещения данных или
их модификации (добавление, удаление,
обновление записей); -
перекрестный
запрос, предназначенный
для отображения результатов
статистических расчетов (суммы,
количества записей, среднего
значения), которые группируются в виде
таблицы по двум наборам
данных, один из которых определяет
заголовки столбцов, а другой
заголовки строк; -
подчиненный
запрос, включающий
в себя инструкцию, находящуюся внутри
другого запроса на выборку или изменение.
На рисунке показана
форма (бланк) запроса-выборки,
предназначенного
для отбора из БД оценок по математике
у студентов группы БТ-61, а на следующем
рисунке — результаты сделанной выборки.

Запрос можно
формировать с использованием логических
(булевых) операций И (AND),
ИЛИ (OR), HE
(NOT).
Например, если требуется
выбрать из БД сведения о результатах
сдачи математики студентами групп
БТ-61 и БТ-62, то необходимо изменить запрос
следующим образом:
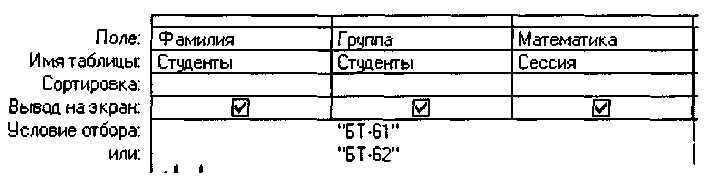
В этом случае из БД
будут отобраны
данные с помощью логической
операции ИЛИ и на экране
появятся сведения о студентах двух
групп — БТ-61 и БТ-62.
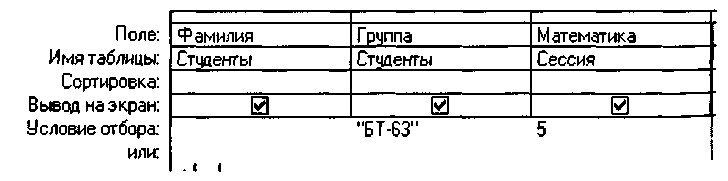
Логическая операция
И используется для решения следующей
задачи. Пусть требуется
выбрать из БД фамилии студентов группы
БТ-63, сдавших математику с оценкой 5. На
следующем рисунке показано, как
формируется запрос с использованием
логической операции И.
Результаты отбора приведены на следующем
рисунке. Рассматриваемые примеры
умышленно выбраны простыми, для того
чтобы можно было проверить полученный
результат даже без использования ЭВМ.
Таблица с результатами
запроса может использоваться при
дальнейшей обработке
данных. В запросе на выборку могут
использоваться не только таблицы
БД, но и таблицы,
полученные ранее в результате запросов.
В запросах можно производить несложные
вычисления. Например, для
подсчета средних баллов нужно при
формировании запроса вначале просуммировать
оценки по четырем предметам, а затем
результат разделить на четыре.
В СУБД MS
Access
это делается так. В очередном свободном
заголовке поля делается следующая
запись:
Результат:
=((Математика)+(Физика)+(Информатика)+(Графика))/4
Чтобы осуществить
отбор записей из базы данных по фамилии,
нужно в качестве условия отбора
использовать следующую запись:
Liке(Фамилия)
Конкретный пример
показан на рисунке слева.
Форма позволяет отобрать данные из
одной или нескольких таблиц и вывести
их на экран, используя стандартный или
созданный пользователем макет. При этом
формы могут
воссоздавать
привычные для
конечного
пользователя документы.
Формы используются не только
для вывода данных из БД, но также
(и, пожалуй, чаще) и для ввода данных. На
рисунке представлена форма, позволяющая
установить средний балл каждого студента
(см. поле «Результат»). Содержание формы
изменяется пользователем в зависимости
от стоящей перед ним задачи.
Отчет содержит ту информацию из БД,
которая должна быть представлена в виде
итогового документа. Обычно отчет
представляется в напечатанном на бумаге
виде (в отличие от таблиц, запросов и
форм, которые чаще
всего отображаются лишь на экране
дисплея). На следующем рисунке представлен
отчет по итогам сессии (естественно,
что это лишь учебный пример
и поэтому он характеризуется исключительной
простотой).
Нестандартная
обработка данных может быть произведена
с помощью макросов
(последовательности
нескольких команд, вызываемых нажатием
одной клавиши) либо с помощью
программ, написанных на языке Access
Visual
Basic.
Такие программы
часто называют модулями.
Для обработки
информации в MS
Access
также используется специализированный
язык SQL (Structured
Query Language —
структурированный язык запросов).
Заметим, что
существенным достоинством СУБД MS
Access
является возможность решать множество
прикладных задач без составления
программ на специализированных языках.
Справка.
Современные СУБД
позволяют работать с огромными объемами
информации. По некоторым оценкам, за
последние 15 лет размеры баз данных
выросли на два
порядка, и процесс этот продолжается.
Сегодня стандартными
считаются базы данных объемом в 1—10
Гбайт, а некоторые из них перешагнули
рубеж 100 Гбайт. По прогнозам специалистов,
развитие крупных информационно-поисковых
систем и хранилищ данных приведет к
созданию БД, вмещающих свыше 10 Тбайт.
В современном мире, где информация становится все более ценным ресурсом, базы данных (БД) остаются неотъемлемым элементом любых информационных систем, а способность извлекать из них данные с максимальной эффективностью становится решающим фактором в успешной работе с этими системами. SQL (Structured Query Language) — специализированный язык программирования, который применяется для управления записями, хранящимися в реляционных базах данных. В рамках SQL существует множество операторов и методов, которые позволяют разработчикам получать нужную информацию из БД.
Эта статья служит практическим руководством для тех, кто хочет узнать, как выбрать данные из таблицы SQL. В рамках данного руководства мы познакомимся с синтаксисом оператора SELECT, изучим возможности фильтрации данных с помощью WHERE, а также рассмотрим объединение данных с помощью GROUP BY и HAVING.
Основы оператора SELECT
SQL, являясь удивительно гибким языком для управления данными, обладает множеством инструментов для работы с информацией, хранящейся в базах данных. Одним из важных и широко используемых инструментов является оператор SELECT, который предоставляет пользователю возможность извлекать информацию из БД. С помощью этого оператора мы можем выбирать необходимые нам столбцы из таблицы, а также применять к данным разнообразные операции.
Синтаксис рассматриваемого оператора достаточно прост и легок для понимания. Он начинается с ключевого слова SELECT, за которым следует перечень столбцов, данные из которых предстоит извлечь. После этого необходимо указать имя таблицы, из которой будут извлекаться данные. Вот как это выглядит на практике:
SELECT field1, field2
FROM data_table;В данном примере field1 и field2 — это конкретные столбцы, которые мы планируем получить, а data_table — имя таблицы, из которой мы хотим получить данные.
Применение оператора SELECT может быть разнообразным. К примеру, если перед нами стоит задача выбора всех столбцов из определенной таблицы, мы можем использовать символ *, который служит универсальным обозначением для всех столбцов:
SELECT * FROM StaffMembers;Такой запрос вернет весь набор данных, содержащихся в таблице StaffMembers.
Кроме того, мы можем использовать SELECT для выбора лишь уникальных значений определенного столбца, исключая повторяющиеся записи, что особенно полезно при анализе данных:
SELECT DISTINCT DivisionID
FROM StaffMembers;В этом примере запрос возвращает список уникальных значений DivisionID из таблицы StaffMembers, то есть устраняются все дублирующиеся элементы.
Оператор SELECT также позволяет применять различные функции агрегирования, такие как COUNT, SUM, AVG и другие. Эти функции являются ключевыми для проведения агрегатных операций, которые позволяют анализировать большие объемы данных с целью получения суммарных, средних значений или других типов агрегатной статистики. Например, мы можем использовать функцию COUNT для подсчета числа строк в таблице:
SELECT COUNT(StaffID)
FROM StaffMembers;Этот запрос вернет общее количество сотрудников. Аналогично, мы можем использовать другие функции агрегирования для вычисления суммы, среднего значения и других агрегатных статистик по данным.
Еще один полезный оператор — ORDER BY, который упорядочивает результаты запроса в соответствии с определенными критериями. Этот оператор позволяет нам сортировать данные, как по возрастанию (ASC), так и по убыванию (DESC). Если мы не укажем направление сортировки явно, по умолчанию будет использоваться порядок возрастания. Вот как это выглядит на практике:
SELECT *
FROM StaffMembers
ORDER BY Surname DESC;В этом примере результаты запроса будут представлены в упорядоченном виде, где данные будут отсортированы по фамилии сотрудников в обратном порядке, начиная с последнего в алфавите и заканчивая первым.
SELECT играет важную роль в SQL, поскольку он определяет, какие конкретные данные будут включены в результаты запроса. Он может быть использован совместно с другими операторами, поэтому перейдем к обсуждению следующего ключевого компонента запроса SQL — оператора WHERE, который позволяет задать конкретные условия для отбора данных.
Использование WHERE для фильтрации данных
Оператор WHERE в SQL обеспечивает фильтрацию данных на основе заданных условий, что позволяет извлекать, обновлять или удалять именно те данные, которые соответствуют определенным критериям.
Если бы оператора WHERE не существовало, мы были бы вынуждены извлекать все данные из таблицы и затем вручную, например, в приложении, фильтровать их для выполнения определенных задач. Это было бы очень неэффективно, особенно для больших баз данных.
WHERE можно использовать с различными операторами, такими как равно (=), не равно (<>), больше (>), меньше (<), больше или равно (>=), меньше или равно (<=), а также более специализированными, вроде, BETWEEN, который позволяет указать диапазон значений, LIKE, предназначенный для поиска по шаблону, и IN, который дает возможность выбрать данные из определенного набора.
Рассмотрим несколько примеров использования WHERE для фильтрации данных.
Применение оператора WHERE с использованием условия равенства (=):
SELECT *
FROM StaffMembers WHERE StaffID = 123456;В этом случае оператор равенства используется для выбора записи, где идентификатор сотрудника точно соответствует числу 123456. Это простой эквивалент оператора равенства в математике.
Использование WHERE с операторами больше (>) или меньше (<):
SELECT *
FROM StaffMembers WHERE Wage > 60000;Здесь используется оператор >, благодаря которому запрос отсеивает ненужное и возвращает нам данные о сотрудниках, чья заработная плата превышает 60000. Этот оператор может быть полезным, если вы ищете записи, которые обладают каким-то значением выше или ниже определенного порога.
Пример использования оператор WHERE с BETWEEN:
SELECT *
FROM StaffMembers WHERE Wage BETWEEN 60000 AND 80000;BETWEEN позволяет выбрать записи, попадающие в определенный диапазон значений. В нашем случае, это все сотрудники, чья зарплата находится в интервале от 60000 до 80000 включительно. Это полезно, когда у вас есть четкий диапазон значений, которые вы хотите извлечь.
Оператор WHERE с использованием LIKE и символов подстановки:
SELECT *
FROM StaffMembers WHERE StaffName LIKE '%ль%';Оператор LIKE используется для поиска данных по шаблонам. В базе данных SQL для обозначения шаблонов применяются два символа подстановки: % заменяет ноль или больше символов, _ — заменяет ровно один символ. Так, в нашем конкретном случае, запрос вернет все записи из таблицы StaffMembers, где имена сотрудников содержат ль. Этот подход часто используется, когда требуется найти данные, точное значение которых не известно, или когда необходимо найти несколько совпадений.
Это лишь несколько примеров возможностей WHERE в SQL. Разнообразие сочетаний и операторов делает его мощным инструментом при работе с данными.
Следующим шагом мы рассмотрим операторы AND, OR и NOT, которые зачастую применяются совместно с WHERE для создания более сложных запросов к базам данных.
dbaas
Использование операторов AND, OR и NOT
AND, OR и NOT являются ключевыми логическими операторами в SQL. Они используются для комбинирования или инвертирования условий в операторах SQL, таких как WHERE, HAVING и др.
-
Оператор
ANDиспользуется для создания запроса, который возвращаетtrue(истину), только когда оба сравниваемых условия являются истинными. Давайте рассмотрим пример:
SELECT * FROM StaffMembers WHERE Wage > 60000 and ExperienceYears > 3;В данном случае оператор AND связывает вместе два критерия отбора: размер заработной платы, превышающий 60000, и опыт работы более трех лет. Результатом выполнения такого запроса станут записи из таблицы, которые удовлетворяют обоим условиям одновременно.
-
Оператор
ORвозвращаетtrue, если хотя бы одно из условий оказывается истинным:
SELECT * FROM StaffMembers WHERE Division = 'Production' OR Division = 'Advertising';Здесь оператор OR соединяет два условия отбора. Запрос выведет те записи из таблицы StaffMembers, в которых указано, что сотрудник принадлежит к отделу Production или Advertising.
-
Оператор
NOTменяет логическое значение условия на противоположное, возвращаяtrue, если условие неверно, иfalse(ложь), если условие верно.
SELECT * FROM StaffMembers WHERE NOT (Division = 'HR');В этом запросе оператор NOT инвертирует условие Division = 'HR'. Запрос вернет все строки из таблицы StaffMembers, где отдел не является HR. Это позволяет формировать запросы, исключающие определенные категории данных.
Эти операторы можно использовать в любых комбинациях для создания сложных условий, например:
SELECT * FROM StaffMembers WHERE (Division = 'Production' OR Division = 'Advertising') AND ExperienceYears > 5;Здесь комбинируются операторы AND и OR для создания сложного условия отбора. Запрос вернет только те строки из таблицы StaffMembers, где отдел это Production ИЛИ Advertising И сотрудники имеют более пяти лет опыта работы.
Агрегирование данных с помощью GROUP BY и HAVING
В SQL GROUP BY и HAVING часто используются вместе для агрегации данных и вычисления разнообразных статистических показателей на основе группировки данных по заранее определенным критериям.
Рассмотрим более подробно оператор GROUP BY. Он используется для группировки строк в результирующем наборе по значениям определенного столбца или группе столбцов. После выполнения группировки можно использовать функции агрегирования, такие как COUNT, SUM, AVG и другие для вычисления статистических данных для каждой отдельной группы.
Пример:
SELECT ClientID, COUNT(PurchaseID)
FROM Purchases
GROUP BY ClientID;В этом примере мы считаем общее количество покупок (PurchaseID), сделанных каждым отдельным клиентом (ClientID).
Оператор HAVING имеет много общего с WHERE, однако ключевое отличие состоит в том, что HAVING применяется уже после того, как была выполнена группировка с помощью GROUP BY. Основная функция HAVING — фильтрация групп на основе уже вычисленных агрегатных значений. Благодаря этому, мы можем отбирать для отображения только те группы, которые удовлетворяют установленным нами критериям.
Пример:
SELECT ClientID, COUNT(PurchaseID)
FROM Purchases
GROUP BY ClientID
HAVING COUNT(PurchaseID) > 3;В этом примере мы видим только тех клиентов (ClientID), у которых количество совершенных ими заказов превышает три.
Заметьте, что HAVING применяется в SQL-запросах исключительно после использования GROUP BY. Нельзя использовать HAVING без предварительной группировки данных с помощью GROUP BY.
В общем, порядок операций в SQL выглядит так:
-
Начинаем с
FROM, где указываем источник данных. -
Затем следует
WHERE, позволяющий отфильтровать данные до их группировки. -
После фильтрации данных применяется оператор
GROUP BY, который объединяет строки в группы. -
Непосредственно после группировки мы используем
HAVINGдля фильтрации групп. -
Далее идет
SELECT, который определяет, какие столбцы будут отображаться в результате запроса. -
И, наконец,
ORDER BY, который сортирует эти результаты в нужном порядке.
Этот порядок операций отражает логику обработки запросов в SQL. Применение условий фильтрации через WHERE происходит до группировки, что позволяет сократить объем обрабатываемых данных. Условия, определенные в HAVING, применяются к уже сформированным группам данных, что дает возможность провести более детальный анализ.
Операторы GROUP BY и HAVING являются неотъемлемыми инструментами для агрегации данных в SQL. Их использование дает возможности для широкого анализа данных, позволяя не только собирать статистические данные, но и выявлять в них определенные закономерности, тренды и паттерны.
Применение JOIN для объединения таблиц
Часто разработчику необходимо выбрать данные из двух таблиц SQL. Для выполнения этой задачи применяется оператор JOIN, позволяющий совмещать данные из двух и более источников, основываясь на совпадении значений в определенных столбцах.
Таблицы в БД обычно имеют столбцы-связки, которые коррелируют с ключами в других таблицах, обеспечивая тем самым возможность связывания данных. Это позволяет автоматически синхронизировать изменения в связанных таблицах, что является неоценимым плюсом при работе с обширными базами данных, где информация разделена между множеством таблиц.
Структура запроса с использованием JOIN выглядит так:
SELECT dataField(s)
FROM tableA
JOIN tableB
ON tableA.dataField = tableB.dataField;В данном случае JOIN применяется для объединения двух таблиц (tableA и tableB). Соединение осуществляется по общему столбцу (dataField). Кроме того, в запросе присутствует выборка определенных столбцов (dataField(s)), которые разработчик хочет увидеть в итоговом результате.
Стоит отметить, что в мире SQL существуют разнообразные виды объединения таблиц, среди которых:
-
INNER JOIN: позволяет нам извлекать исключительно те строки, которые обладают соответствующими записями в обеих таблицах, то есть там, где условия совпадения выполнены:
SELECT Purchases.PurchaseID, Clients.ClientName
FROM Purchases
INNER JOIN Clients
ON Purchases.ClientID = Clients.ClientID;
-
LEFT (OUTER) JOIN: применяется тогда, когда требуется извлечь все строки из таблицы, расположенной слева (то есть из той, что указана первой в запросе), и соответственно, те строки из таблицы справа, которые имеют совпадения. В случае отсутствия пар в правой таблице, результаты для этих строк будут содержать значениеNULL:
SELECT Clients.ClientName, Purchases.PurchaseID
FROM Clients
LEFT JOIN Purchases
ON Clients.ClientID = Purchases.ClientID;
-
RIGHT (OUTER) JOIN: действует аналогичноLEFT JOIN, но наоборот. Здесь мы получаем все записи из правой таблицы, дополняемые соответствующими данными из левой таблицы. Если совпадений для записей из правой таблицы не обнаружено, то вместо данных из левой таблицы ставитсяNULL:
SELECT Clients.ClientName, Purchases.PurchaseID
FROM Clients
RIGHT JOIN Purchases
ON Clients.ClientID = Purchases.ClientID;
-
FULL (OUTER) JOIN: этот тип объединения предоставляет нам все строки из обеих таблиц, для которых есть соответствующие записи. Другими словами, он объединяетLEFTиRIGHT JOIN. Если в первой таблице есть строки, для которых не найдено пары во второй таблицы, то соответствующие поля второй таблицы в этих строках будут содержатьNULL. Аналогично, если записи из второй таблицы не имеют совпадений в первой, то для этих записей столбцы, принадлежащие первой таблице, будут содержатьNULL:
SELECT Clients.ClientName, Purchases.PurchaseID
FROM Clients
FULL OUTER JOIN Purchases
ON Clients.ClientID = Purchases.ClientID;
Стоит отметить, что хотя FULL (OUTER) JOIN является стандартной функцией SQL, он не поддерживается во всех SQL-системах. Например, в MySQL нет встроенной поддержки FULL (OUTER) JOIN, поскольку их можно эмулировать с помощью комбинации LEFT JOIN и UNION:
SELECT Clients.ClientName, Purchases.PurchaseID
FROM Clients
LEFT JOIN Purchases
ON Clients.ClientID = Purchases.ClientID
UNION
SELECT Clients.ClientName, Purchases.PurchaseID
FROM Purchases
LEFT JOIN Clients
ON Clients.ClientID = Purchases.ClientID
WHERE Clients.ClientID IS NULL;Этот запрос сначала выполняет внешнее левое соединение, присоединяя записи из Purchases к Clients. Затем присоединяются записи из Clients к Purchases, которые не были выбраны в первом запросе (т.е. те, где ClientID является NULL). Наконец, он объединяет результаты этих двух запросов.
В этом разделе мы обсудили разные типы JOIN в SQL. Каждый из этих объединений позволяет нам с гибкостью управлять тем, какие именно данные из связанных таблиц мы хотим увидеть в результирующем наборе.
Заключение
В данном руководстве мы на практических примерах изучили использование таких операторов в SQL, как SELECT, WHERE, ORDER BY, JOIN, GROUP BY и HAVING. Эти операторы предоставляют пользователям обширные возможности для обработки информации, позволяя проводить сложные аналитические запросы и извлекать максимальную пользу из хранимых данных. Надеемся, что теперь вы понимаете, как использовать SQL для выборки данных из БД!
Детали файла
| Имя файла: | 4172.Экз.01;ЭЭ.02;1 |
| Размер: | 110 Kb |
| Дата публикации: | 2015-03-09 04:20:39 |
| Описание: | |
| Информационные технологии в психологии — Электронный экзамен
Список вопросов теста (скачайте файл для отображения ответов): _____________ — это свойство алгоритма, означающее, что процесс решения задачи разделен на отдельные шаги и, соответственно, алгоритм представляет последовательность указаний, команд, определяющих порядок выполнения шагов процесса |
|
| Для скачивания этого файла Вы должны ввести код указаный на картинке справа в поле под этой картинкой —> | |
| ВНИМАНИЕ: | |
| Нажимая на кнопку «Скачать бесплатно» Вы подтверждаете свое полное и безоговорочное согласие с «Правилами сервиса» | |
К каким сетям имеют отношение X.25, Frame Relay, ATM, TCP/IP?
(*ответ*) к глобальным вычислительным сетям с коммутацией пакетов
к глобальным вычислительным сетям с коммутацией каналов
к глобальным вычислительным сетям с выделенными каналами связи
Как в корпоративных вычислительных сетях называется язык описания гипертекстовых документов, который, не будучи языком программирования, представляет собой средство обработки документов (слово из четырех английских букв)?
(*ответ*) HTML
Как в локальных вычислительных сетях называется совокупность правил, определяющих алгоритм взаимодействия устройств, программ, систем обработки данных, процессов или пользователей?
(*ответ*) протокол
Как называется вычислительная система, включающая в себя несколько компьютеров, терминалов и других аппаратных средств, соединенных между собой линиями связи, обеспечивающими передачу данных (введите два слова)?
(*ответ*) вычислительная сеть
Как называется главный компьютер, управляющий работой иерархической сети?
(*ответ*) сервер
Как называется запись в реляционной базе данных?
(*ответ*) кортеж
Как называется инструкция для отбора нужных записей из БД в соответствии с определенными условиями?
(*ответ*) запрос
Как называется комплект букв, цифр и специальных символов, оформленных в соответствии с едиными требованиями?
(*ответ*) шрифт
Как называется короткая, как правило, мигающая линия, показывающая позицию рабочего поля, в которую будет помещен вводимый символ или элемент документа?
(*ответ*) курсор
Как называется корпоративная вычислительная сеть?
(*ответ*) Intranet
Ethernet
Internet
Как называется модель данных, в которой данные одного уровня подчинены данным другого уровня, а связи между элементами образуют древовидную структуру?
(*ответ*) иерархическая
Как называется набор правил, защищающих данные от случайных изменений или удалений с помощью механизма поддержки корректности связей между связанными таблицами?
(*ответ*) целостность данных
Как называется набор форматирующих команд, сохраняемый под своим именем для многократного использования?
(*ответ*) стиль
форматирование
список
Как называется объект, предназначенный для создания документа, представляющего информацию в необходимой пользователю форме, и который впоследствии может быть распечатан?
(*ответ*) отчет
Как называется поле или минимальный набор полей, однозначно определяющих каждую строку таблицы?
(*ответ*) первичный ключ
поле
запись
Как называется последовательность команд, запускаемая одним нажатием клавиши на клавиатуре или кнопки на экране дисплея?
(*ответ*) макрос
Как называется последовательность строк, в которых содержатся данные одного типа?
(*ответ*) список
Как называется программа просмотра WWW (слово на русском языке из 7 букв)?
(*ответ*) браузер
Как называется процедура проверки пользователя, аппаратуры или программы для получения доступа к определенной информации или ресурсу?
(*ответ*) аутентификация
Как называется работающая в диалоговом режиме программа обработки данных, обеспечивающая взаимодействие с пользователем при помощи выводимых на экран дисплея прямоугольных таблиц?
(*ответ*) электронная таблица
Power Point
Microsoft Access
В статье рассказывается:
О чем речь? Выборка данных – это, как следует из названия, отбор информации из базы данных по заданным критериям. За этот процесс отвечают определенные операторы, которые формируют тип запроса и необходимые критерии.
Как сделать? Данная задача является не самой простой, так как приходится разбираться в сложном синтаксисе. Однако уловив последовательность команд, дело остается за малым – получить и обработать необходимую информацию.
В статье рассказывается:
- Суть выборки данных
- Выборка данных через оператор SELECT
- Группировка данных при выборке
- Нюансы выборки данных из ORM систем
-
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Суть выборки данных
Любая реляционная СУБД имеет такую функцию, как выборка данных (команда SELECT). Она является одной из самых востребованных, но при этом и сложнейших в плане синтаксиса. Однако, при всей сложности и объёмности предложений SQL, выборка данных из базы не представляет какой-то проблемы.

Чтобы успешно произвести выборку, необходимо чётко понимать, какая последовательность ключевых слов в запросе необходима и каким будет результат по каждому ключевому слову. Мы будем рассматривать примеры по мере усложнения. Начнём с самых простых случаев выборки данных из базы и пока не будем использовать какие-либо клаузулы или предикаты (уточняющие фразы) для определения условий, фильтрации данных в выборке и сортировке отфильтрованных значений.
Приступая к работе с выборками данных, всегда помните одно важное правило: команда SELECT в SQL-запросе всегда вернёт вам данные в формате таблицы. И неважно, насколько сложный у вас запрос. SQLite и любая другая РСУБД будет возвращать результат выборки данных в виде таблицы.
Кроме того, необходимо располагать ключевые слова в правильном порядке:
- Начинаем с ключевого слова SELECT.
- После него идут круглые скобки, где мы указываем колонки, из которых нам необходимо получить значения.
- Затем следует ключевое слово FROM.
- Пишем имя таблицы, к которой обращаемся за данными.
- Прописываем остальные ключевые слова (тоже в строгой последовательности, но сейчас не будем останавливаться на этом подробно, дабы не запутаться).
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Уже скачали 34066
Соблюдая этот нехитрый порядок ключевых слов и помня о том, что на выходе получится таблица, вы сможете без проблем делать запросы в SQL.
Выборка данных через оператор SELECT
Элементами оператора SELECT в SQL являются блоки, определяющие параметры выражения.
Для MySQL обязательный блок — первый, сам SELECT.
Всего в SELECT есть три блока:
- Собственно SELECT: те данные, которые мы хотим получить из базы. В каком-то смысле аналогичен переименованию и проекции в реляционной алгебре.
- FROM: устанавливает диапазон данных в выборке (сообщает, откуда начинать выбирать). По аналогии с реляционной алгеброй это аргумент операции.
- WHERE: обязательное условие выборки данных, которому они должны соответствовать. В реляционной алгебре подобное называется операцией выборки.
Блок SELECT
Наподобие проекции:
SELECT col1, col2, …
Помещает в выборку только данные из указанных столбцов. Чтобы выбрать все без исключения столбцы, применяем синтаксис SELECT *.
Наподобие переименования:
SELECT col1 as name1, col2 as name2, …
Не только выбираем данные из нужных столбцов, но и переименовываем столбцы.
Это самые базовые варианты использования SELECT, но его возможности намного шире. Например, можно подставить значение или функцию (в том числе оператор). Если написать:
SELECT ‘Hello World!’ as Hello;
То получим следующую выборку:
При наличии в данных таблицы operands
запрос к базе будет иметь вид:
SELECT a, b, a+b as c FROM operands
Результат:
| a | b | c |
| 1 | 10 | 11 |
| 2 | 15 | 17 |
| 3 | 20 | 23 |
В SQL имеется масса встроенных функций, которые могут работать с временны́ми данными, преобразовывать типы, обрабатывать статистику и т. п.
Скачать
файл
Блок FROM
Этот блок используется для того, чтобы уточнить аргумент SELECT. Если брать самые простые случаи, то во FROM указывают имя таблицы (отношения).

Согласно принципам реляционной алгебры, можно указать в качестве аргумента FROM подзапрос — выборку данных из другого запроса. Для этого подзапросу присваивают псевдоним:
SELECT a+b FROM (SELECT 1 as a, 2 as b) as tbl1;
Дарим скидку от 60%
на обучение «Аналитик больших данных» до 27 апреля
Уже через 9 месяцев сможете устроиться на работу с доходом от 150 000 рублей
Забронировать скидку
Кроме того, посредством блока FROM можно вычислять декартовы произведения и делать конкатенацию. В этом нам поможет JOIN, бинарный оператор.
Предположим, у нас есть таблица bin:
По запросу в базу
SELECT * FROM bin b1 JOIN bin b2 JOIN bin b3;
получим декартово произведение bin×bin×bin:
| a | a | a |
| 0 | 0 | 0 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 1 | 0 |
| 0 | 0 | 1 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 1 | 1 |
JOIN и является оператором декартова произведения. Есть несколько вариантов JOIN: INNER JOIN, используемый по умолчанию, NATURAL, OUTER RIGHT JOIN, OUTER LEFT JOIN, OUTER FULL JOIN.
Блок WHERE
Необходим для того, чтобы задать критерии выборки данных, и представляет собой реляционную операцию выборки.
К примеру, по запросу:
SELECT * FROM bin WHERE a>0;
вы получите:
Помните, что любое переименование осуществляется только после выборки. Поэтому, например, выражение.
Только до 28.04
Скачай подборку материалов, чтобы гарантированно найти работу в IT за 14 дней
Список документов:
ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
Чтобы получить файл, укажите e-mail:
Введите e-mail, чтобы получить доступ к документам
Подтвердите, что вы не робот,
указав номер телефона:
Введите телефон, чтобы получить доступ к документам
Уже скачали 52300
SELECT a as b FROM bin WHERE b>0;
неправильное: здесь блок WHERE видит только аргумент FROM, а переименование — ещё не видит.
Исходя из этого правила, блок WHERE можно использовать только совместно с блоком FROM, и выражение вроде:
SELECT 1 WHERE TRUE;
просто не будет работать.
Но, если очень нужно, можно задействовать dual («пустую» таблицу, из которой напрямую ничего нельзя выбрать — вернётся ошибка):
SELECT 1 FROM dual WHERE TRUE;
Этот вариант вполне рабочий.
Dual можно указывать, если по синтаксису SQL требуется именно таблица.
В качестве аргумента WHERE можно задавать что угодно, лишь бы это выражение преобразовывалось в булев тип данных.
Группировка данных при выборке
Чтобы сгруппировать данные в SELECT-запросе при формировании выборки, применяют конструкцию group by, где перечисляются те же колонки таблицы, что и в SELECT. Рассмотрим пример выборки данных в таблицу bills по группам:
— все счета в таблице
create table bills(
id integer,
d date, — дата выставления счета
summ double precision ,— сумма счета
constraint pk_bills primary key (id)
);
— вставляем данные
insert into bills
values(1, date ‘2008-01-01’, 5.5);
insert into bills
values(2, date ‘2008-02-01’, 3.14);
insert into bills
values(3, date ‘2008-03-01’, 10.14);
insert into bills
values(4, date ‘2008-01-01’, 7.2);
insert into bills
values(5, date ‘2008-02-01’, 6.4);
insert into bills
values(6, date ‘2008-03-01’, 2.5);
commit;
— выводим данные в сгруппированном виде
select t.d, t.summ from bills t
group by t.d, t.summ
Вообще-то группы в выборках данных используются не так часто. Можно переписать вышеприведённый пример по-другому, с сортировкой. Но всё меняется, если нам нужна одна из групповых (агрегатных) функций:
- avg([DISTINCT|ALL] column) — среднее арифметическое по всей выбранной колонке;
- count(*|[DISTINCT|ALL] соlumn) — число элементов в выборке данныхлибо в группе, которую определяет указанная колонка;
- sum([DISTINCT | ALL] соlumn) — сумма всех значений в выбранной колонке;
- max(соlumn) — максимальное значение в колонке;
- min(соlumn) — минимальное значение в колонке.
С помощью ключевого слова DISTINCT можно убрать из колонки повторяющиеся значения. ALL означает, что нужно по умолчанию обработать все значения. Ключевое слово * используется, когда поля со значением null тоже нужно обрабатывать.
Следите за тем, чтобы в вашем коде для MySQL не было пробелов между скобкой и названием функции.
Рассмотрим случай, когда выбираемыми данными являются агрегатные функции. Если такая функция применяется без group by, то она охватит абсолютно все элементы выборки; в противном же случае — будет использована для каждой группы данных по отдельности. Как бы то ни было, в SELECT групповые колонки таблицы не должны смешиваться с негрупповыми.
— статистика по всем месяцам года
select count(*) as «количество записей
max(t.summ) as «макс. сумма»,
min(t.summ) as «мин. сумма»,
avg(t.summ) as «средняя сумма»,
sum(t.summ) as «общая сумма»
from bills t;
— статистика по каждому конкретному месяцу
select t.d as «месяц», count(1) as «количество записей»,
max(t.summ) as «макс. сумма»,
min(t.summ) as «мин. сумма»,
avg(t.summ) as «средняя сумма»,
sum(t.summ) as «общая сумма»
from bills t
group by t.d
Условные выражения и конструкция having (отбирающая группу) тоже могут содержать агрегатные функции.

— выбираем те группы элементов, чья общая сумма превышает 12
select t.d as «месяц», count(*) as «количество записей»,
max(t.summ) as «макс. сумма»,
min(t.summ) as «мин. сумма»,
avg(t.summ) as «средняя сумма»,
sum(t.summ) as «общая сумма»
from bills t
group by t.d
having sum(t.summ)>12
Выборка данных любого объёма представляет собой их множество. А это значит, что над ней можно производить операции для множества, а именно:
- UNION — объединять в итоговой выборке данных элементы двух запросов;
- INTERSECT — выводить только пересекающиеся записи (которые соответствуют обоим запросам);
- EXCEPT — исключать из конечной выборки элементы, присутствующие лишь в первом запросе.
К запросам, которые участвуют в этих операциях, предъявляются несколько требований.
Количество столбцов в них должно совпадать, причём столбцы, стоящие на одинаковых позициях, должны ещё иметь одинаковый тип.
Допускаются только данные простых типов в столбцах (то есть, никаких blob и т. п.).
В MySQL5 есть только поддержка UNION. Oracle отличается тем, что EXCEPT в ней используется для иных целей, а исключение записей производится командой MINUS.
— from dual работает только в Oracle
— в MySQL запросы не могут быть заключены в круглые скобки.
select 1 as i from dual
UNION
select 2 as i from dual
UNION — можно также применить INTERSECT и EXCEPT
select 2 as i from dual
UNION
select 3 as i from dual;
Нюансы выборки данных из ORM систем
При работе с моделями данных, содержащими только одну сущность, никаких сложностей с ORM не возникает. Разберём простой пример. Предположим, у нас есть сущность Пользователь (User) с двумя атрибутами — именем (Name) и ID.
public class User {
@Id
@GeneratedValue
private int id;
private String name;
//Getters and Setters here
}
Как же вытащить из базы данных экземпляр данной сущности? Очень просто: с помощью одного метода объекта EntityManager:
EntityManager em = entityManagerFactory.createEntityManager();
User user = em.find(User.class, id);
А вот в случае, когда есть отношение «один-ко-многим», всё становится намного интереснее:
public class User {
@Id
@GeneratedValue
private int id;
private String name;
@OneToMany
private List<Address> addresses;
//Getters and Setters here
}
Наверное, вы уже задаётесь вопросом, а нужно ли делать выборку данных по адресам, извлекая экземпляр пользователя. Верный ответ — по-разному: если эти адреса нам нужны, то да, делаем, если нет — то нет. Как правило, в ORM доступны два способа выбрать зависимую запись: жадный и ленивый. Последний применяется по умолчанию во многих ORM. Однако если ваш код выглядит вот так:
EntityManager em = entityManagerFactory.createEntityManager();
User user = em.find(User.class, 1);
em.close();
System.out.println(user.getAddresses().get(0));
то вы получите исключение “LazyInitException”. Оно всегда вызывает недоумение у начинающих программистов, испытывающих недостаток опыта работы с ORM. Пора вводить новые понятия — сессия в транзакции, Detached и Attached экземпляры сущности.
Нам нужно присоединить сущность к сессии, чтобы зависимые данные оказались в выборке. Казалось бы, самое простое решение — не закрывать транзакции сразу. Но оно порождает другую проблему: транзакции удлиняются, и риск взаимной блокировки растёт. Попробовать сократить транзакции? Это возможно, однако множество коротких транзакций порождает ситуацию, когда стая крохотных комариков способна закусать огромного медведя.
С базами данных такое тоже, увы, возможно. Возрастание мелких транзакций создаёт проблемы с производительностью.
Но, как уже говорилось, адреса далеко не всегда требуются при получении данных о пользователе, и только бизнес-логика определяет, попадут адреса в запрос на выборку данных или нет. То есть, придётся прописывать дополнительные проверки. Как-то всё слишком сложно получается, не правда ли?
Но можно пойти иным путём и просто сменить тип выборки:
public class User {
@Id
@GeneratedValue
private int id;
private String name;
@OneToMany(fetch = FetchType.EAGER)
private List<Address> addresses;
//Getters and Setters here
}
Не то чтобы это сильно помогло. Конечно, мы обойдётся без надоевшего LazyInit и постоянных проверок на то, прикреплена ли сущность к сессии. Но вот проблем с производительностью таким образом не решим: даже если адреса нам требуются не всегда, мы всё равно каждый раз их запрашиваем из памяти сервера.
Усталость от ORM и переход на другие фреймворки — нередкое явление среди бэкенд-разработчиков. Многие выбирают Spring JDBC, в котором реляционные данные можно преобразовать в объектные, причём в полуавтоматическом режиме. Необходимо писать запросы под каждую ситуацию, где требуется та или иная совокупность атрибутов. А если нужны одни и те же структуры данных, то код можно переиспользовать.
Это обеспечивает большую степень гибкости. К примеру, не нужно создавать новый объект-сущность, достаточно выбрать всего один атрибут:
String name = this.jdbcTemplate.queryForObject(
«select name from t_user where id = ?»,
new Object[]{1L}, String.class);
Хотя можно выбрать и объект, как обычно:
User user = this.jdbcTemplate.queryForObject(
«select id, name from t_user where id = ?»,
new Object[]{1L},
new RowMapper<User>() {
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
User user = new User();
user.setName(rs.getString(«name»));
user.setId(rs.getInt(«id»));
return user;
}
});
Если дописать в этот код ещё несколько строк и грамотно составить запрос к SQL (так, чтобы исключить проблему n+1 запроса), то можно получить и список адресов, необходимых пользователю.
Читайте также!
Квантовый компьютер: что такое и зачем нужны

Подведём итог всего вышесказанного. Запросы к БД позволяют осуществлять операции выборки данных, их фильтрации, сортировки. Посредством запроса в базу можно делать расчёты, объединять данные из нескольких таблиц, удалять, редактировать, добавлять записи в таблицу. Типов запросов довольно много, и это делает запрос гибким мощным инструментом, подходящим для различных нужд (тип выбирается по назначению запроса).