
Содержание:
- Что такое файл robots.txt?
- Для чего нужен файл robots.txt?
- Нюансы при использовании файла robots.txt
- Терминология файла robots.txt
- Директивы в robots.txt
- Директива User-agent
- Директива Disallow
- Директива Allow
- Алгоритм интерпретации директив Allow и Disallow
- Пустые Allow и Disallow
- Директива Sitemap
- Директива Clean-param
- Директива Host
- Директива Crawl-delay
- Комментарии в файле robots.txt
- Маски в robots.txt: для чего нужны и как правильно использовать
- Директивы в robots.txt
- Общие правила составления robots.txt
- Создание robots.txt
- Ручное создание robots.txt
- Онлайн создание файла robots.txt
- Как проверить robots.txt
- Проверки в Яндекс.Вебмастер: http://webmaster.yandex.ru/robots.xml
- Проверки в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
- Проверка с помощью Google Robots.txt Parser и Matcher Library
- Другие особенности работы с robots.txt
- Создание robots.txt
- Файл robots.txt по типам сайтов
- Файл robots.txt для Landing Page
- Файл robots.txt для интернет-магазина
- Готовые шаблоны файла robots.txt для популярных CMS
- Файл robots.txt для WordPress
- Файл robots.txt для 1С-Битрикс
- Файл robots.txt для OpenCart
- Файл robots.txt для MODx
- Файл robots.txt для Diafan
- Файл robots.txt для Drupal
- Файл robots.txt для NetCat
- Файл robots.txt для Joomla
- Популярные файлы robots.txt под задачи
- Закрыть от индексации полностью сайт в robots.txt
- Закрыть от индексации все страницы кроме главной в robots.txt
- Закрыть одну страницу в robots.txt
- Пример robots.txt для Яндекса
- Пример robots.txt для Google
- Пример robots.txt для всех поисковиков
- Популярные вопросы про файл robots.txt
- В заключение
Любой владелец многостраничного сайта заинтересован в получении трафика из поисковых систем, как рекламного, так и органического. Чтобы сайт по запросу пользователей выходил в выдаче Google и Яндекс (не важно топ 3, топ 10 или топ 100) необходимо, чтобы сайт прошел индексацию поисковыми системами. Индексация сайта — это процесс «сканирования» сайта поисковыми «роботами» в результате чего они получают информацию о всех его страниц и имеющемся на нем контенте.
На любом сайте есть не только контент для пользователей, но и различные системные файлы, которые не должны попадать в индексацию и соответственно в выдачу. Когда поисковый робот начинает сканировать сайт, для него нет разницы, системный перед ним файл или нет — он просканирует все. При этом на посещение сайта у поискового робота отведено ограниченное количество времени, поэтому важно, чтобы он проиндексировал именно нужные нам страницы. Иначе робот посчитает сайт бесполезным и позиции сайта могут в итоге снизиться в поисковой выдаче.
Со стороны владельца сайта можно повлиять на процесс сканирования сайта, прописывая определенные правила для поисковых роботов. Для того, чтобы поисковые роботы проиндексировали только необходимые для нас страницы, обязательно нужно создавать файл robots.txt с набором правил и фильтров.
Что такое файл robots.txt?
Файл robots.txt – это текстовый файл в формате .txt, который размещается в корневой папке сайта и содержит инструкции по обходу страниц, которые необходимо исключить из индексации поисковых систем.
Для сайта https://discript.ru/ путь размещения следующий: https://discript.ru/robots.txt
В нем есть своя структура, правила, и в целом он в некотором роде выполняет функцию «фильтра». Говоря проще, именно при помощи robots.txt мы указываем, какие страницы сайта робот должен сканировать, а какие – нет.
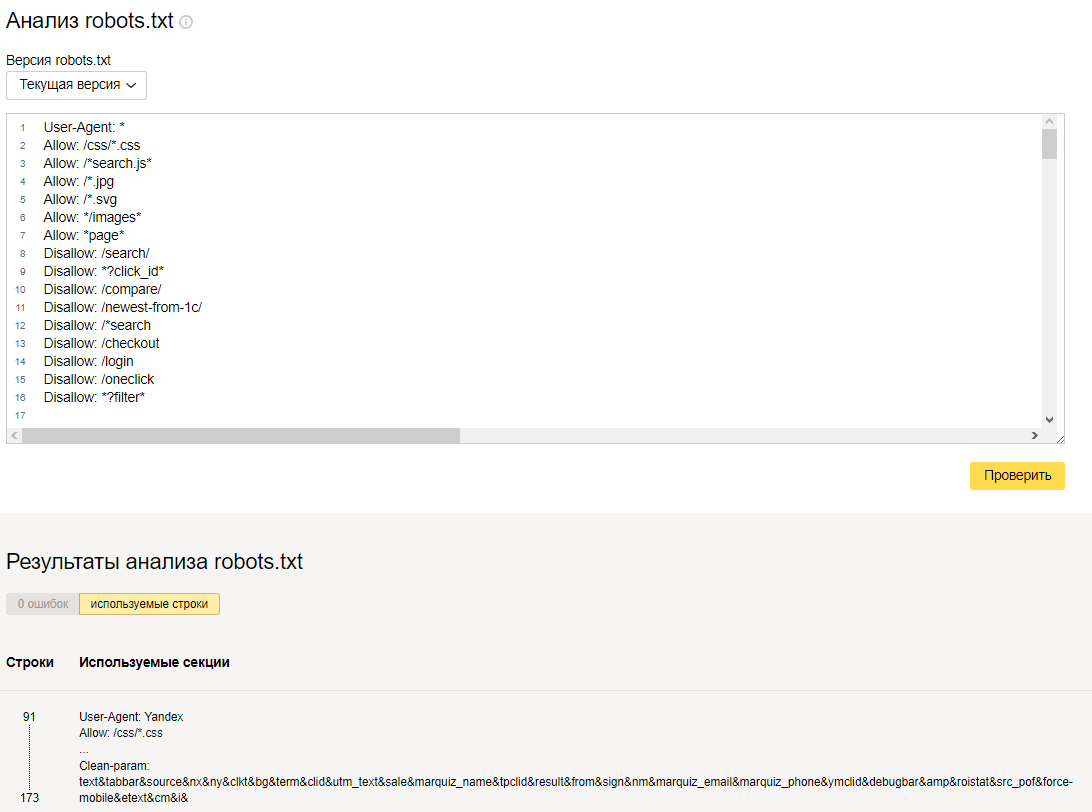
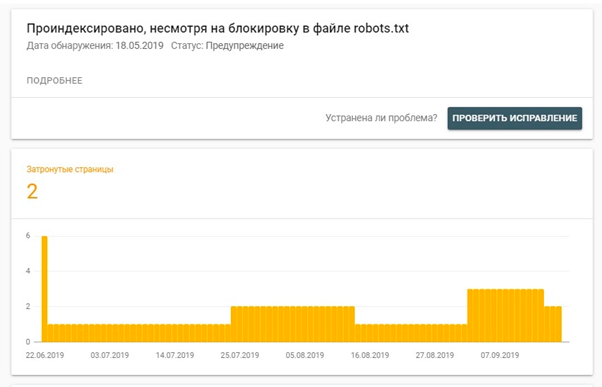
Пример файла robots.txt в панели Яндекс Вебмастер
Google: файл robots.txt носит рекомендательный характер и не служит для 100% ограничением для поисковых роботов.

Источник справка Google: https://developers.google.com/search/docs/crawling-indexing/robots/intro?hl=ru
Для чего нужен файл robots.txt?
Когда поисковый робот (краулер / паук) заходит на сайт, то в первую очередь он ищет именно этот файл.
При этом пауки в любом случае могут обойти страницы сайта — независимо от того, есть ли на нем robots.txt или нет. Просто если файл robots.txt есть, то роботы с высокой вероятностью будут следовать правилам, прописанным в файле.
А если он есть, но при этом неправильно настроен, то сайт и вовсе может выпасть из поиска или просто не будет проиндексирован.
Файл robots позволяет исключить из индекса:
- Мусорные страницы.
- Дубли страниц.
- Служебные страницы.
Правильная настройка файла robots.txt позволяет сохранить крауленговый бюджет и повысить частоту сканирования нужных разделов.
К тому же вы можете запретить сканирование дополнительных файлов, таких как:
- Дубли изображений в сжатом формате.
- Дополнительные стили сайта.
- Скрипты.
Но данные элементы следует запрещать к сканированию аккуратно, т.к. данное действие не должно мешать поисковым системам интерпретировать контент.
Нюансы при использовании файла robots.txt
Обратите внимание, что при работе с файлом robots.txt есть свои нюансы:
- Правила используемые в robots.txt не всегда интерпретируются всеми поисковыми системами одинаково.
Например, директива «Clean-param» считается ошибкой при интерпретации Google. - Для поисковых роботов правила являются рекомендациями и не всегда роботы следуют им.
- Если страница закрыта в файле robots.txt, но при этом на данную страницу есть ссылки, то Google может добавить такую страницу в индекс. И для удаления подобной страницы из поисковой выдачи требуются другие инструменты.
Терминология файла robots.txt
В файле robots.txt основная работа происходит с Директивами и Директориями, важно не запутаться и понимать отличия между терминами:
Директория — это папка, в которой находятся файлы вашей системы управления.
Директива — это список команд, инструкции в robots.txt для одного или нескольких поисковых роботов при помощи которых производится управление индексацией сайта. В файле robots.txt используются 5 директив.
Директивы в robots.txt
5 директив используемых в robots.txt:
- User-agent
- Disallow
- Аllow
- Sitemap
- Clean-param
А так же:
- Маски
- Комментарии
Существует 2 устаревших директивы:
- Host
- Crawl-delay
Директива User-agent
User-agent — это директива для определения, какому поисковому боту необходимо выполнять указанные инструкции.
Все поисковые роботы начинают обработку robots.txt с проверки записи User-agent и определения подходящих инструкций работы с сайтом.
Примеры User-agent в robots.txt:
# Указывает директивы для всех роботов одновременно
User-agent: *
# Указывает директивы для всех роботов Яндекса
User-agent: Yandex
# Указывает директивы для всех роботов Google
User-agent: Googlebot
Через robots.txt можно обратиться не только к главному роботу поисковой системы, но и к вспомогательным роботам, например, в Яндексе есть робот, который индексирует изображения: YandexImages или робот, который индексирует видео: YandexVideo.
Существует мнение, что роботы лучше индексируют сайт, если к ним обращаться напрямую, а не через общую инструкцию, но с точки зрения синтаксиса разницы нет никакой.
Если в директиве User-agent указать конкретного робота, то учитывать правила общего назначения (User-agent: *) указанный робот не будет.
Кроме того, в robots.txt не имеет значения регистр символов. То есть одинаково правильно будет записать: User-agent: Googlebot или User-agent: googlebot.
Таким образом, директива User-agent указывает только на робота (или на всех сразу), а уже после нее должна идти команда или команды с непосредственным указанием команд для выбранного робота.
Директива Disallow
Disallow — запрещающая директива. Она запрещает поисковому роботу обход каталогов, адресов или файлов сайта. Данная директива является наиболее используемой. Путь к тем файлам, каталогам или адресам, которые не нужно индексировать, прописываются после слеша «/».
Рассмотрим несколько примеров
Как в robots.txt запретить индексацию сайта:
User-agent: * # — Инструкции для всех роботов.
Disallow: / # — Закрыты от индексации все страницы сайта.
Данный пример закрывает от индексации весь сайт для всех роботов.
Как robots.txt запретить индексацию папки wp-includes для всех роботов:
User-agent: * # — Инструкции для всех роботов.
Disallow: /wp-includes # — Закрыт от индексации раздел wp-includes.
Данный пример закрывает для индексации все файлы, которые находятся в этом каталоге.
А вот если вам, например, нужно запретить индексирование всех страниц с результатами поиска только от робота Яндекс, то в файле robots.txt прописывается следующее правило:
User-agent: Yandex # — Инструкции для бота Yandex.
Disallow: /search # — Закрыт от индексации раздел search.
Запрет на индексацию в этом случае распространяется именно на страницы, у которых в URL есть «/search».
Директива Disallow допускает работу с масками, которые позволяют производить операции с группой файлов и папок.
Директива Allow
Allow — разрешающая директива, логически противоположная директиве Disallow. То есть она принудительно открывает для индексирования указанные каталоги, файлы, адреса. Директива имеет синтаксис, сходный с Disallow.
Пример, как в robots.txt запретить индексацию сайта кроме некоторых страниц:
User-agent: * # — Инструкции для всех роботов.
Disallow: / # — Закрыты от индексации все страницы сайта.
Allow: /blog # — Открыт для индексирования раздел blog.
Запрещается индексировать весь сайт, кроме страниц, начинающихся с /blog.
Если же необходимо разрешить индексировать все страницы, в адресе которых присутствует вхождение blog, то следует использовать конструкцию:
User-agent: * # — Инструкции для всех роботов.
Disallow: / # — Закрыт от индексации все страницы сайта.
Allow: /*blog # — Открыт для индексирования любые страницы с вхождением blog в URL.
Иногда директивы Allow и Disallow используются в паре. Это может понадобиться для того, чтобы открыть роботу доступ к подкаталогу, который расположен в каталоге с запрещенным доступом.
Алгоритм интерпретации директив Allow и Disallow
Когда бот определяет свои инструкции по User-agent, то встает вопрос, по какому алгоритму интерпретировать правила. Ведь одно правило, может противоречить другому. Или например, нужно открыть для индексирования вложенный раздел, но корневой закрыть от индексации.
Роботы интерпретируют robots.txt последовательно сортируя инструкции по длине URL от короткого к длинному. При этом если длина правила совпадает для Allow и Disallow, то более приоритетное правилом является Allow.
Рассмотрим механизм на примере:
Вам необходимо, чтобы раздел /catalog/mebel/divan/ индексировался роботом, а раздел /catalog/mebel/ был закрыть от роботов.
При этом Вы имеете следующий файл robots.txt
User-agent: *
Disallow: /catalog/avto/
Allow: /catalog/mebel/divan/
Disallow: /catalog/test/
Allow: /
Disallow: /catalog/mebel/
То робот информацию прочитает так:
User-agent: * # — Инструкции для всех роботов.
Allow: / # — Сайт доступен для индексации
Disallow: /catalog/avto/ # — Раздел /catalog/avto/ закрыт для индексирования.
Disallow: /catalog/test/ # — Раздел /catalog/test/ закрыт для индексирования.
Disallow: /catalog/mebel/ # — Раздел /catalog/mebel/ закрыт для индексирования.
Allow: /catalog/mebel/divan/ # — Раздел /catalog/mebel/divan/ доступен для индексирования, при этом раздел /catalog/mebel/ и другие подразделы данного каталога закрыты от индексирования.
Зная, как боты интерпретируют правила из robots.txt дает больше возможностей по составлению правил для индексирования сайта.
Пустые Allow и Disallow
Если в файле robots.txt присутствуют пустые Allow и Disallow, то роботы интерпретируют их так:
Пустой Disallow — соответствует директиве Allow: /, т.е. разрешает индексировать весь сайт.
Пустой Allow — не интерпретируется роботом.
Директива Sitemap
Sitemap — директива указывающая ссылку на карту сайта: sitemap.xml. Данная директива позволяет боту быстрее найти файл sitemap.xml.
Robots.txt с указанием адреса карты сайта:
User-agent: * # — Инструкции для всех роботов.
Disallow: /page # — Закрыт от индексации раздел page.
Sitemap: http://www.site.ru/sitemap.xml
В файле robots.txt допускается использование нескольких директив Sitemap
Директиву Sitemap можно размещать с отступом в строку от других директив. Что в свою очередь значит, что данная директива не привязывается к определенному User-agent и достаточно указать 1 раз в файле robots.
Примеры допустимого использования директивы:
Второй вариант:
Директива Clean-param
Clean-param — директива позволяет исключить из индексации страницы с динамическими get-параметрами. Такие страницы могут отдавать одинаковое содержимое, имея различные URL (например, UTM). Данная директива позволяет сэкономить крауленговый бюджет за счёт исключения из индексирования страниц дублей. Clean-param интерпретирует только Яндекс, роботы Google на данную директиву выдадут ошибку.
Директива Clean-param применима только для Яндекса (Google выдаст ошибку), поэтому без особой надобности её использовать не рекомендуется.
Примечания:
- Иногда для закрытия таких страниц используется директива Disallow. В некоторых случаях рекомендуем использовать Clean-param, так как эта директива позволяет передавать основному URL или сайту некоторые накопленные показатели, например ссылочные.
- Директива Clean-Param может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
- Директива имеет ограничение на 500 символов. Если требуется больше символов, то необходимо использовать несколько директив Clean-Param.
Рекомендации к применению:
- При использовании UTM-меток
- Дубли генерируемые get-параметрами
- При использовании идентификаторов в get-параметрах.
Синтаксис директивы Clean-param:
Clean-param: parm1&parm2&parm3 [Путь]

Через & указаны параметры, которые необходимо не учитывать,
[Путь] — адрес, для которого применяется инструкция. Если данного параметра нет, то применяется ко всем страницам на сайте.
В директиве Clean-param допускается использовать регулярные выражения, но с ограничениями.
При использовании регулярных выражений необходимо использовать следующие символы: a-z0-9.-/*_.
Рассмотрим на примере страницы со следующим URL:
- www.site.ru/page.htm
- www.site.ru/page.html?&parm1=1&parm2=2&parm3=3
- www.site.ru/page.html?&parm1=1&parm4=4
Данные страницы являются дублями и имеют одинаковый контент. Поэтому нам необходимо с помощью директивы Clean-param удалить из индексирования страницы с параметрами:
- parm1
- parm2
- parm3
- parm4
Ограничение учета параметров только для раздела /page
User-agent: *
Disallow: /catalog
Clean-param: parm1&parm2&parm3&parm4 /page # Исключить параметры parm1, parm2, parm3, parm4 и только для page.html
Ограничение учета параметров только для всего сайта
User-agent: *
Disallow: /catalog
Clean-param: parm1&parm2&parm3&parm4 # Исключить параметры parm1, parm2, parm3, parm4 на всех страницах сайта.
Пример использования регулярных выражений. Ограничение учета параметров для страниц в URL, у которых есть вхождение page.
User-agent: *
Disallow: /catalog
Clean-param: parm1&parm2&parm3&parm4 /*page # Исключить параметры parm1, parm2, parm3, parm4 для всех страниц содержащих вхождение в URL page.
Директива Host
Host — директива указывающая поисковым роботам Яндекса главное зеркало ресурса.
Директива Host перестала учитываться поисковой системой Яндекс в марте 2018 года. (В Google никогда не учитывалась). Данную директиву можно удалить из файла, но на зеркалах необходимо настроить 301-редирект. Подробнее по ссылке: https://yandex.ru/blog/platon/pereezd-sayta-posle-otkaza-ot-direktivy-host
Данная директива применялась для проектов, где доступ к сайту осуществляется по нескольким адресам.
Например, сайт мог быть доступен по следующим адресам:
- site.ru
- www.site.ru
- old.site.ru
- site.com
Но контент на данных страницах полностью дублировался.
Пример файла robots с директивой Host:
User-agent: Yandex
Disallow: /page
Host: site.ru # Указание основного зеркала сайта
Директива Crawl-delay
Crawl-delay — директива позволяющая задать скорость обхода страниц поисковым ботам для вашего ресурса. Данная директива учитывались только Яндексом. На текущий момент не поддерживается совсем.
Директиву Crawl-delay с 22 февраля 2018 года Яндекс перестал учитывать. Подробнее по ссылке https://yandex.ru/support/webmaster/robot-workings/crawl-delay.html
Если необходимо указать скорость обхода для поискового бота используйте панель вебмастера https://yandex.ru/support/webmaster/service/crawl-rate.html#crawl-rate
Комментарии в файле robots.txt
Комментарии в robots.txt — поясняющие заметки, которые не интерпретируются роботами и позволяют пользователю получить уточнения по работе директив.
Комментарии пишутся после символа решетки «#» и действуют до конца строки.
Комментарии упрощают работу и помогают быстрее сориентироваться в файле. В комментарии добавляют актуальную и полезную информацию, например, ссылку на партнерку:

Некоторые вебмастера добавляют в комментариях к robots.txt рекламные тексты.
В комментариях robots.txt можно прописать все, что угодно, однако идеальный комментарий— это тот, в котором мало строк, но много смысла.
Маски в robots.txt: для чего нужны и как правильно использовать
Маска в robots.txt — это условная запись, в которую входят названия целой группы папок или файлов. Маски используются для того, чтобы одновременно совершать операции над несколькими файлами (или папками) и обозначаются спецсимволом-звездочкой — «*».
На самом деле, использование масок не только упрощает работу, оно зачастую просто необходимо. Предположим, у вас на сайте есть список файлов в папке /documents/. Среди этих файлов есть презентации в формате .pdf, и вы не хотите, чтобы их сканировал робот. Значит эти файлы нужно исключить из поиска.
Как это сделать? Можно перечислить все файлы формата .pdf вручную:
- Disallow: /documents/admin.pdf
- Disallow: /documents/town.pdf
- Disallow: /documents/leto.pdf
- Disallow: /documents/sity.pdf
- Disallow: /documents/europe.pdf
- Disallow: /documents/s-112.pdf
Но если таких файлов сотни, то указывать их придется очень долго, поэтому куда быстрее просто указать маску *.pdf, которая скроет все файлы в формате pdf в рамках одной директивы:
- Disallow: /documents/*.pdf
Специальный символ «*», который используется при создании масок, обозначает любую последовательность символов, в том числе и пробел.
Пример использования маски.
User-agent: *
Disallow: /
Disallow: *.pdf # — Закрыты от сканирования все файлы pdf.
Disallow: admin*.pdf # — Закрыты от сканирования файлы pdf из раздела admin.
Disallow: a*m.pdf # — Закрыты от сканирования файлы pdf из разделов начинающихся на a и m перед расширением файла .pdf.
Disallow: /img/*.* # — Закрыты от сканирования все элементы в папке img.
Allow: /*blog # — Открыты для индексирования любые страницы с вхождением blog в URL.
Общие правила составления robots.txt
Очень важно грамотно работать с файлом robots.txt, иначе можно собственноручно отправить на индексацию документы, которые индексировать не планировалось.
- наличие файла robots.txt на сайте;
- в правильном ли месте он расположен;
- грамотно ли он составлен;
- насколько он работоспособен, т.е. доступны ли указанные в нем документы для индексации.
Файл robots.txt должен располагаться исключительно в корневой папке сайта, т.е. он должен быть доступен по адресу site.ru/robots.txt.
Не допускается наличие вложений, например, site.ru/page/robots.txt. Если файл robots.txt располагается не в корне сайта (и у него другой URL), то роботы поисковых систем его не увидят и будут индексировать все страницы сайта.
При этом важно помнить, что файл robots.txt привязан к адресу домена вплоть до протокола. То есть для http и https требуется 2 разных robots.txt, даже если затем адреса совпадают. Также один и тот же файл нельзя использовать для субдоменов (хостов) и других портов.
Один robots.txt действителен для всех файлов во всех подкаталогах, которые относятся к одному хосту, протоколу и номеру порта.
Корректность файла robots.txt можно оценить, проверив его по следующим пунктам:
- Один файл robots.txt.Файл должен быть один для каждого сайта и называться он должен robots.txt.
- robots.txt отсутствует или он закрыт от индексирования (Disallow: /);
- Размещение robots.txt в корне сайта. Файл robots.txt должен располагаться в корневой папке сайта. Если он расположен в другом месте, то роботы его не увидят и будут индексировать весь сайт (включая файлы, которые индексировать не нужно).
- Заглавные буквы в названии не используются.
Неверно:
site.ru/RoBoTs.txt
Верно:
site.ru/robots.txt
-
Запрещено использовать кириллицу в директориях robots.txt. Чтобы указывать названия кириллических доменов, нужно использовать Punycode для их преображения. Адреса сайтов также указывают в кодировке UTF-8, включающей коды символов ASCII.
Для перевода кирилического URL используйте инструмент: https://www.punycoder.com
Неверно:
User-agent: Yandex
Disallow: /корзина
Sitemap: сайт123.рф/sitemap.xmlВерно:
-
Инструкции пишутся отдельно для каждого робота, т.е. в директиве User Agent не допускается никаких перечислений. Если хотите назначить правила для всех роботов, то необходимо использовать User-agent: *. В файле robots.txt знак «*» — это любое число любых символов;
Неверно:
User-agent: Yandex, Google, Mail
Disallow: /Верно:
User-agent: Yandex
Disallow: /User-agent: Google
Disallow: /User-agent: Mail
Disallow: / -
Есть несколько правил для одного агента, например, несколько правил «User-agent: Yandex». В правильно составленном файле такое правило может быть только одно.
Неверно:
User-agent: Yandex
Disallow: /User-agent: Yandex
Disallow: /catalogUser-agent: Yandex
Disallow: /testВерно:
User-agent: Yandex
Disallow: /
Disallow: /catalog
Disallow: /test -
Каждая директива должна начинаться с новой строки;
Неверно:
User-agent: *
Disallow: /catalog Disallow: /new Allow: /testВерно:
User-agent: *
Disallow: /catalog
Disallow: /new
Allow: /test -
1 директива = 1 параметр, т.е. например, Disallow: /admin, и никаких Disallow: /admin /manage и т.д. в одной строчке;
Неверно:
User-agent: *
Disallow: /catalog /new /testВерно:
User-agent: *
Disallow: /catalog
Disallow: /new
Allow: /test -
В начало строки не ставится пробел;
Неверно:
User-agent: *
Disallow: /catalog
Disallow: /new
Allow: /testВерно:
User-agent: *
Disallow: /catalog
Disallow: /new
Allow: /test -
Параметр директивы должен быть прописан в одну строку;
Неверно:
User-agent: *
Disallow: /catalog_
new_cat
Disallow: /new
Allow: /testВерно:
User-agent: *
Disallow: /catalog_new_cat
Disallow: /new
Allow: /test -
Параметры директивы не нужно добавлять в кавычки, также они не требуют закрывающих точки с запятой;
Неверно:
User-agent: *
Disallow: «/catalog_new_cat»
Disallow: /new;
Allow: /testВерно:
User-agent: *
Disallow: /catalog_new_cat
Disallow: /new
Allow: /test -
Комментарии допускаются после знака #;
Неверно:
User-agent: *
# Этот комментарий заставит игнорировать строчку Disallow: /catalog_new_cat
Disallow: /new
Allow: /testВерно:
User-agent: *
Disallow: /catalog_new_cat # Этот комментарий заставит учитывать строку
Disallow: /new
Allow: /test -
Перед правилом отсутствует директива User-agent. Любое правило в robots.txt всегда начинается с User-agent.
Неверно:
Disallow: /catalog
Disallow: /new
Allow: /testВерно:
User-agent: *
Disallow: /catalog
Disallow: /new
Allow: /test -
Пустые строки между директивами. Правильная настройка robots.txt запрещает наличие пустых строк между директивами «User-agent», «Disallow» и директивами, следующими за «Disallow» в рамках текущего «User-agent».
Неверно:
User-agent: Yandex
Disallow: /
User-agent: Google
Disallow: /catalog
User-agent: Mail
Disallow: /testUser-agent: Yandex
Disallow: /
User-agent: Yandex
Disallow: /
Disallow: /catalogDisallow: /test
Верно:
User-agent: Yandex
Disallow: /User-agent: Google
Disallow: /catalogUser-agent: Mail
Disallow: /testUser-agent: Yandex
Disallow: /
Disallow: /catalog
Disallow: /test -
Некорректные адреса. Например, путь к файлу Sitemap должен указываться полностью, включая протокол.
Неверно:
User-agent: *
Disallow: /catalog
Disallow: /new
Allow: /testsitemap: /sitemap
Верно:
- Слишком большой (более 32Кб), недоступный по каким-либо причинам или пустой robots.txt будет трактоваться как полностью разрешающий;
- В robots.txt допускается использовать более 2048 директивы (команд).
- Максимальная длина одного правила — 1024 символа. Но такая ошибка встречается довольно редко.
- Некорректный тип контента. Должен быть: text/plain.
Ошибка, когда на уровне хостинга robots.txt имеет кодировку HTML:
Проверить тип контента можно на сайте https://bertal.ru/
Четкое соблюдение вышеописанных правил при создании и настройке файла robots.txt имеет огромное значение. Незамеченный или пропущенный слэш, звездочка или запятая могут привести к тому, что сайт закроется от индексации полностью. То есть даже незначительная разница в синтаксисе приводит к существенным отличиям в функционале.
Создание robots.txt
Файл robots.txt нужно разместить в корневой папке, то есть в той, которая называется так же, как и ваш движок и содержит в себе индексный файл index.html и файлы системы управления, на базе которой и сделан сайт.
Чтобы загрузить в эту папку файл robots.txt можно использовать панель управления сервером, админку в CMS, Total Commander или другие способы.
Ручное создание robots.txt
Чтобы самостоятельно создать файл robots.txt не потребуется никаких дополнительных программ. Достаточно будет любого текстового редактора, например, стандартного блокнота, notepade++, Microsoft Word и другие текстовые редакторы.
Чтобы создать robots.txt просто сохраните файл под таким именем и с расширением .txt., и уже после этого вносите в него все необходимые инструкции в зависимости от стоящих перед вами задач.
На некоторых движках уже есть встроенная функция, которая позволяет создать robots.txt. Если у вас ее нет, то можно использовать специальные модули или плагины. Но в целом, нет никакой разницы, каким именно способом вы создадите robots.txt.
Онлайн создание файла robots.txt
В случае, когда у вас не один, а несколько сайтов, и создание файлов robots.txt будет занимать долгое время, можно воспользоваться онлайн-сервисами, которые генерируют robots.txt. автоматически. Но учтите, что такие файлы могут требовать ручной корректировки, поэтому все равно нужно понимать правила их составления и знать особенности синтаксиса.
Для составления robots.txt можете воспользоваться нашим инструментом: http://tools.discript.ru/robots-check/. Он позволяет выгрузить robots.txt, как с вашего сайта, так и загрузить готовый шаблон для CMS и скорректировать уже под Ваши задачи.
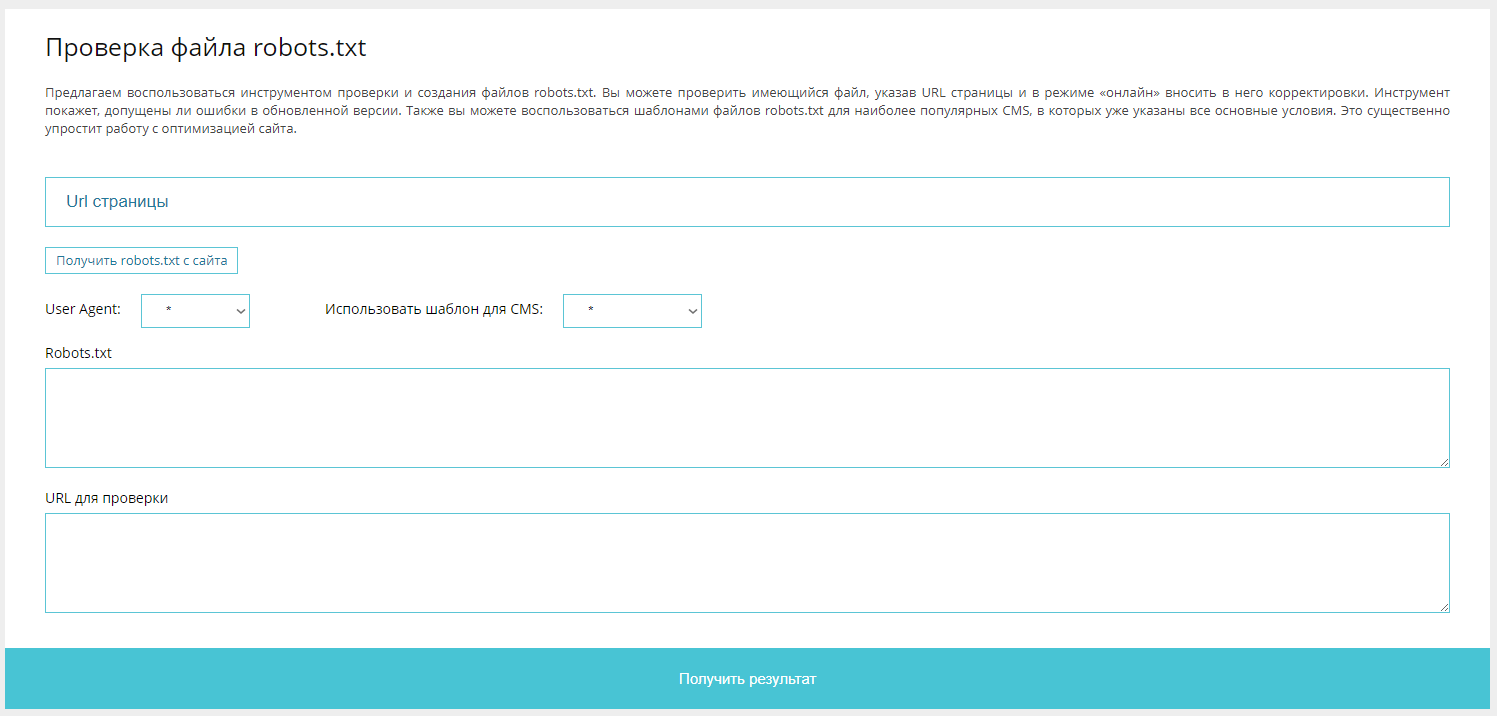
Далее в статье также можно найти готовые шаблоны robots.txt.
Как проверить robots.txt
Проверить, насколько правильно составлен robots.txt, можно при помощи:
Инструмента http://tools.discript.ru/robots-check/.
С его помощью вы можете проверить свой файл и внести в него корректировки в режиме онлайн. Для этого укажите URL страницы в соответствующем поле. Инструмент покажет, допущены ли ошибки в обновленной версии. Также вы можете использовать подготовленные шаблоны файлов robots.txt для наиболее популярных CMS, в которых уже указаны все основные условия.
Инструмент позволяет скачать итоговый файл и сразу разместить его на сайте.
Проверки в Яндекс.Вебмастер: http://webmaster.yandex.ru/robots.xml
Здесь анализируется каждая строка содержимого поля «текст robots.txt» и директивы, которые он содержит. Здесь также можно увидеть, какие страницы открыты для индексации, а какие — закрыты.
Проверки в Google: https://www.google.com/webmasters/tools/robots-testing-tool
Здесь можно проверить, содержится ли в файле запрет на сканирование роботом Googlebot определенных адресов на ресурсе:
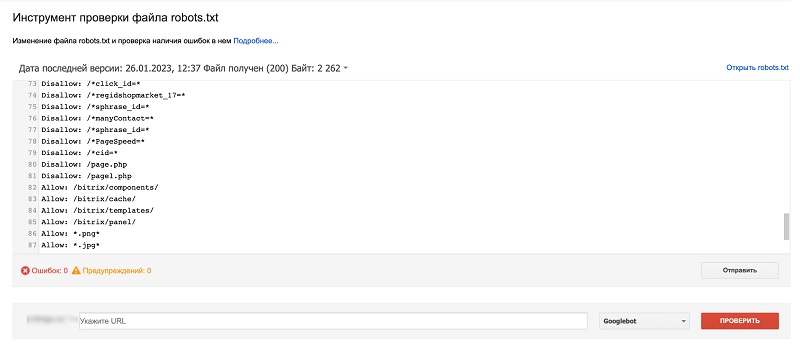
Проверка с помощью Google Robots.txt Parser и Matcher Library
В 2019 году Google представил доступ к своему парсеру. Скачать его можно с GitHab по ссылке https://github.com/google/robotstxt
Данная библиотека используется Google для парсинга файла robots.txt. Если Вы хотите получать файл, способом, как это делает Google, то можете воспользоваться библиотекой запустив её у себя.
Другие особенности работы с robots.txt
-
Страницы, закрытые с помощью файла robots.txt, могут быть проиндексированы в Google. Например, когда на них ведет много внутренних и внешних ссылок.
В таком случае в панели Google Search Console можно видеть такой отчет:
По этому вопросу в Google справочнике указано:
Файл robots.txt не предназначен для блокировки показа веб-страниц в результатах поиска. Если на других сайтах есть ссылки на вашу страницу, содержащие ее описание, то она все равно может быть проиндексирована, даже если роботу Googlebot запрещено ее посещать. Если файл robots.txt запрещает роботу Googlebot обрабатывать веб-страницу, она все равно может показываться в Google, но связанный с ней результат поиска может не содержать описания и выглядеть следующим образом:
Источник: https://support.google.com/webmasters/answer/6062608?hl=ru
Поэтому, чтобы закрыть от индексирования страницы, которые содержат конфиденциальную информацию, нужно использовать более надежные методы: не только robots.txt, но и html-теги.
Если нужно закрыть внутри зоны документ, то устанавливается следующий код:
— запрещено индексировать содержимое и переходить по ссылкам на странице;
Или (полная альтернатива):
Такие теги показывают роботам, что страницу не нужно показывать в результатах поиска, а также не нужно переходить по ссылкам на ней.
Однако при использовании только мета-тега краулинговый бюджет будет расходоваться намного быстрее, поэтому лучше всего применять комбинированный способ. Он, к тому же, с большим приоритетом выполняется поисковыми роботами.
-
Для изображений настройка robots.txt выглядит следующим образом:
Чтобы скрыть определенное изображение от робота Google Картинок
User-agent: Googlebot-Image
Disallow: /images/dogs.jpg
Чтобы скрыть все изображения с вашего сайта от робота Картинок
User-agent: Googlebot-Image
Disallow: /
Чтобы запретить сканирование всех файлов определенного типа (в данном случае GIF)
User-agent: Googlebot
Disallow: /*.gif$
Файл robots.txt важен для продвижения, потому что дает поисковикам указания, которые напрямую влияют на результативность работы сайта. Например, в нем можно установить запрет на индексацию «мусорных» или некачественных страниц, закрыть страницу с доступом в административную панель, страницы с приватными данными, дублирующие документы и т.д.
-
Рекомендуется закрывать от индексации следующие страницы:
- страницы входа в CMS-систему вида «/bitrix», «/login», «/admin», «/administrator», «/wp-admin».
- служебные папки вида «cgi-bin», «wp-icnludes», «cache», «backup»
- страницы авторизации, смены пароля, оформления заказа: «basket&step=», «register=», «change_password=», «logout=».
- результаты поиска «search», «poisk».
- версию для печати вида: «_print», «version=print» и аналогичные.
- страницы совершения действия вида «?action=ADD2BASKET», «?action=BUY».
- разделы с дублированным и неуникальным контентом, скажем, RSS-фиды: «feed», «rss», «wp-feed».
Если на сайте есть ссылки на страницы, которые закрыты в файле robots.txt, то рекомендуется убрать эти ссылки, чтобы не передавать на них статический вес.
Наиболее часто дублями страниц, попавшими в индекс, являются документы с неопределенными в БД GET-параметрами. Примерами таких параметров являются UTM-метки (и прочие метки рекламных кампаний). Если на сайте не настроен rel=»canonical», то потенциальные данные дубли лучше закрывать от индексации.
Список наиболее частых параметров:
- openstat
- from
- gclid
- utm_source
- utm_medium
- utm_campaign
- utm_прочие
- yclid
Следует помнить, что GET параметры могут идти после знака «?», либо после знака «&» (если их более одного). Поэтому для закрытия GET параметров необходимо для каждого знака указывать отдельное правило:
- Disallow: *?register=*
- Disallow: *®ister=*
Либо не указывать ни один из данных знаков (не самый лучший вариант для коротких GET параметров т.к. они могут быть частью более длинных вариантов. Например, GET параметр id входит в GET параметр page_id):
- Disallow: *register=*
Пример закрытия таких страниц:
- Disallow: *openstat=*
- Disallow: *from=*
- Disallow: *gclid=*
- Disallow: *?utm_*
- Disallow: *&utm_*
- Disallow: *yclid=*
Пример закрытия всех GET параметров главной страницы:
- Disallow: /?*
Также для закрытия страниц с неопределенными GET параметрами можно сделать следующее: закрыть на сайте все GET параметры, принудительно открыв при этом нужные GET параметры.
Но нужно осторожно использовать данный метод, чтобы случайно не закрыть важные страницы на сайте.
Пример использования:
Disallow: /*?* # закрываем все страницы с GET параметрами
Allow: /*?page=* # открываем для сканирования страницы пагинации
# дополнительно можно закрыть страницы пагинации, которые содержат два GET параметра
Disallow: /*?*&page=*
Disallow: /*?page=*&*Используя сервис Screaming Frog Seo Spider можно также определить, какие еще страницы необходимо закрыть от индексации. Часто такие страницы можно найти с помощью дублей тегов и мета-тегов. Найти их помогут фильтры по дублям title/h1/description.
Также можно выгрузить проиндексированные страницы в Яндекс.Вебмастер и проверить, какие еще из них стоит исключить из индекса:
- Одним из требований поисковиков Google и Yandex является открытие для индексации файлов JavaScript и CSS, так как они используются ими для анализа удобства сайта и его ранжирования.

Определить весь список ресурсов, которые нужно открыть для индексации, можно при помощи Google Search Console.
Для этого указываем URL для сканирования:
Далее нажимаем на ссылку «Изучить просканированную страницу»
Переходим на вкладку «Скриншот» и нажимаем на «Проверить страницу на сайте»:
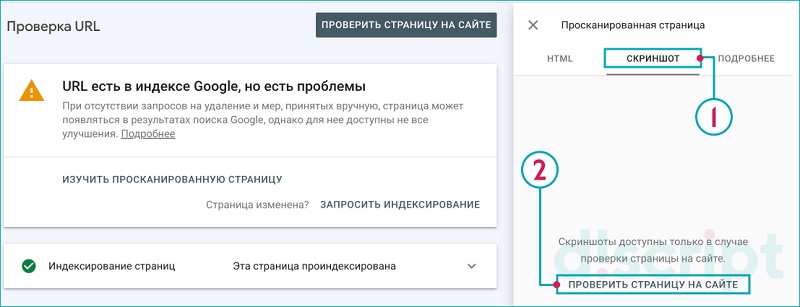
Получаем результаты:
- Как видит страницу Google.
- Какие элементы JS/CSS и др. не подгрузились
И ресурсы, требующие внимания
Файл robots.txt по типам сайтов
Рассмотрим различные файлы robots.txt по типам сайтов от Landing Page до интернет-магазинов.
Файл robots.txt для Landing Page
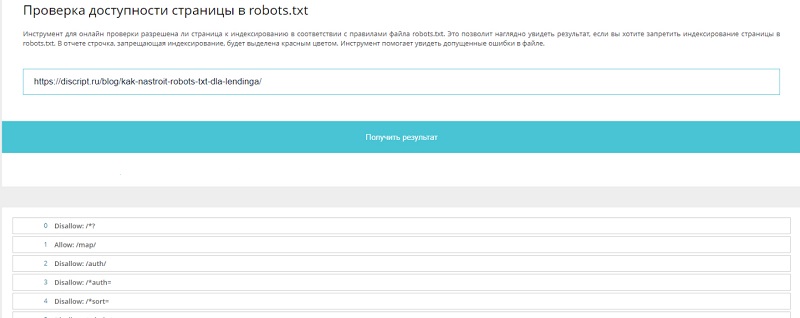
Файл robots.txt для Landing Page рассмотрели в рамках отдельной статьи: https://discript.ru/blog/kak-nastroit-robots-txt-dla-lendinga/
Оптимизация файла для Landing Page отличается от любого другой сайта, тем что он запрещает индексирование любых разделов, кроме главной страницы. При этом файлы CSS-стилей и JS-кода остаются доступными для роботов.
User-agent: *
Allow: /images/
Disallow: /js/
Disallow: /css/
User-agent: Googlebot
Allow: /
User-agent: Yandex
Allow: /images/
Disallow: /js/
Disallow: /css/
Файл robots.txt для интернет-магазина
При составлении файла robots.txt необходимо понимать, что у интернет-магазина встречается функционал, который не встречается у других типов сайтов (информационные, сайты услуг).
К такому функционалу интернет-магазина можно отнести:
- Страницы с результатами поиска (чтобы избежать дубли страниц);
- Страницы меток и тегов;
- Страницы сортировок товаров;
- Страницы фильтров товаров;
- Страницы корзины;
- Страницы оформления заказов;
- Страницы личных кабинетов;
- Страницы входа;
- Страницы регистрации.
Часто такие разделы могут формировать мусорные страницы и страницы дубли. По этому такие страницы у интернет-магазина рекомендуется закрывать в файле robots.txt. Напомним, что в индексе необходимо оставить страницы полезные для пользователей.
Для составления файла robots.txt для интернет-магазина необходимо учитывать структуру вашего проекта и сделать анализ на ошибки и мусорные страницы.
Но мы подготовили для Вас шаблоны на основе популярных CMS. Обычно интернет-магазины создаются на Bitrix, OpenCart, WordPress, MODx. Вы можете использовать подходящий шаблон под вашу CMS и доработать файл под нюансы вашего проекта.
Готовые шаблоны файла robots.txt для популярных CMS
Предлагаем готовые файлы robots.txt для различных CMS
Файл robots.txt для WordPress
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /cgi-bin
Disallow: /*?
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Disallow: *?attachment_id=
Disallow: */page/
Allow: */uploads
Allow: /wp-*.js
Allow: /wp-*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-*.svg
Allow: /wp-*.pdf
Sitemap: http://site.ru/sitemap.xml
Файл robots.txt для 1С-Битрикс
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /*index.php$
Disallow: /admin/
Disallow: /bitrix/
Disallow: /cgi-bin/
Disallow: /auth/
Disallow: /personal/
Disallow: /upload/
Disallow: /search/
Disallow: /*/search/
Disallow: /*/slide_show/
Disallow: /*/gallery/*order=*
Disallow: /*?
Disallow: /*&print=
Disallow: /*?print=
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*action=*
Disallow: /*bitrix_*=
Disallow: /*backurl=*
Disallow: /*back_url=*
Disallow: /*back_url_admin=*
Disallow: /*print_course=Y
Disallow: /*course_id=
Disallow: /*pagen_*
Disallow: /*page_*
Disallow: /*showall
Disallow: /*show_all=
Disallow: /*clear_cache=
Disallow: /*order_by
Disallow: /*sort=
Allow: /map/
Allow: /bitrix/components/
Allow: /bitrix/cache/
Allow: /bitrix/*.js
Allow: /bitrix/templates/
Allow: /bitrix/panel/
Allow: /bitrix/*.css
Allow: /bitrix/images/
Sitemap: http://site.ru/sitemap.xml
Файл robots.txt для OpenCart
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=vDisallow: /*?page=
Disallow: /*&page=
Disallow: /index.php?route=product/manufacturer
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/category
Disallow: /*compare-productsvDisallow: /*search
Disallow: /*cart
Disallow: /*checkout
Disallow: /*login
Disallow: /*logout
Disallow: /*vouchersvDisallow: /*wishlist
Disallow: /*my-account
Disallow: /*order-history
Disallow: /*newsletter
Disallow: /*return-add
Disallow: /*forgot-password
Disallow: /*downloads
Disallow: /*returns
Disallow: /*transactions
Disallow: /*create-account
Disallow: /*recurring
Disallow: /*address-book
Disallow: /*reward-points
Disallow: /*affiliate-forgot-password
Disallow: /*create-affiliate-account
Disallow: /*affiliate-loginvDisallow: /*affiliates
Allow: /catalog/view/javascript/
Allow: /catalog/view/theme/*/
Allow: /image/
Sitemap: http://site.ru/sitemap.xml
Файл robots.txt для MODx
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /manager/
Disallow: /assets/components/
Disallow: /core/
Disallow: /connectors/
Disallow: /mgr/
Disallow: /index.php
Disallow: /*?
Allow: /*.js
Allow: /*.css
Allow: /images/
Sitemap: http://site.ru/sitemap.xml
Файл robots.txt для Diafan
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /m/
Disallow: *?
Disallow: /news/rss/
Disallow: /cart/
Disallow: /search/
Allow: /image/
Allow: /*.js
Allow: /*.css
Sitemap: http://site.ru/sitemap.xml
Файл robots.txt для Drupal
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /includes/
Disallow: /misc/
Disallow: /modules/
Disallow: /profiles/
Disallow: /scripts/
Disallow: /themes/
Disallow: /database/
Disallow: /sites/
Disallow: /updates/
Disallow: /profile
Disallow: /profile/*
Disallow: /index.php
Disallow: /changelog.txt
Disallow: /cron.php
Disallow: /install.mysql.txt
Disallow: /install.pgsql.txt
Disallow: /install.php
Disallow: /install.txt
Disallow: /license.txt
Disallow: /maintainers.txt
Disallow: /update.php
Disallow: /upgrade.txt
Disallow: /xmlrpc.php
Disallow: /admin/
Disallow: /comment/
Disallow: /comment/reply/
Disallow: /contact/
Disallow: /logout/
Disallow: /filter/tips/
Disallow: /node/add/
Disallow: /search/
Disallow: /top-rated-
Disallow: /messages/
Disallow: /book/export/
Disallow: /user2userpoints/
Disallow: /myuserpoints/
Disallow: /user/register/
Disallow: /user/password/
Disallow: /user/login/
Disallow: /user/logout/
Disallow: /tagadelic/
Disallow: /referral/
Disallow: /aggregator/
Disallow: /files/pin/
Disallow: /your-votes
Disallow: /comments/recent
Disallow: /?q=admin/
Disallow: /?q=comment/
Disallow: /?q=filter/tips/
Disallow: /?q=node/add/
Disallow: /?q=search/
Disallow: /?q=user/password/
Disallow: /?q=user/register/
Disallow: /?q=user/login/
Disallow: /?q=user/logout/
Disallow: /*/edit/
Disallow: /*/delete/
Disallow: /*/export/html/
Disallow: /taxonomy/term/*/0$
Disallow: /*/edit$
Disallow: /*/outline$
Disallow: /*/revisions$
Disallow: /*/contact$
Disallow: /*downloadpipe
Disallow: /node$
Disallow: /node/*/track$
Disallow: /*&
Disallow: /*%
Disallow: /*?page=0
Disallow: /*section
Disallow: /*order
Disallow: /*?sort*
Disallow: /*&sort*
Disallow: *register*
Disallow: *login*
Disallow: /*votesupdown
Disallow: /*calendar
Disallow: /*index.php
Disallow: /*?
Allow: /*?page=
Allow: /images/
Allow: /*.js
Allow: /*.css
Sitemap: http://site.ru/sitemap.xml
Файл robots.txt для NetCat
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /*route=account/
Disallow: /*route=affiliate/
Disallow: /*route=checkout/
Disallow: /index.php?route=product/product*&manufacturer_id=
Disallow: /admin
Disallow: /catalog
Disallow: /download
Disallow: /export
Disallow: /system
Disallow: /*?sort=
Disallow: /*&sort=
Disallow: /*?order=
Disallow: /*&order=
Disallow: /*?limit=
Disallow: /*&limit=
Disallow: /*?filter_name=
Disallow: /*&filter_name=
Disallow: /*?filter_sub_category=
Disallow: /*&filter_sub_category=
Disallow: /*?filter_description=
Disallow: /*&filter_description=
Disallow: /*?tracking=
Disallow: /*&tracking=vDisallow: /*?page=
Disallow: /*&page=
Disallow: /index.php?route=product/manufacturer
Disallow: /index.php?route=product/compare
Disallow: /index.php?route=product/category
Disallow: /*compare-productsvDisallow: /*search
Disallow: /*cart
Disallow: /*checkout
Disallow: /*login
Disallow: /*logout
Disallow: /*vouchersvDisallow: /*wishlist
Disallow: /*my-account
Disallow: /*order-history
Disallow: /*newsletter
Disallow: /*return-add
Disallow: /*forgot-password
Disallow: /*downloads
Disallow: /*returns
Disallow: /*transactions
Disallow: /*create-account
Disallow: /*recurring
Disallow: /*address-book
Disallow: /*reward-points
Disallow: /*affiliate-forgot-password
Disallow: /*create-affiliate-account
Disallow: /*affiliate-loginvDisallow: /*affiliates
Allow: /catalog/view/javascript/
Allow: /catalog/view/theme/*/
Allow: /image/
Sitemap: http://site.ru/sitemap.xml
Файл robots.txt для Joomla
Ссылка на готовый файл robots.txt.
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /modules/
Disallow: /plugins/
Disallow: /tmp/
Disallow: /templates
Disallow: *catid
Disallow: *0&idvDisallow: *id
Disallow: /finvil/
Disallow: /index.php*
Disallow: /index2.php*
Disallow: /index.html
Disallow: /application.php
Disallow: /component/
Disallow: /*mailto/
Disallow: /*.pdf
Disallow: /*print=
Disallow: /*tag
Disallow: /*%
Disallow: /search*
Disallow: /*start
Disallow: /*=atom
Disallow: /*=rss
Disallow: /*print=1
Disallow: /*?
Disallow: /*&
Allow: /index.php?option=com_xmap&sitemap=1&view=xml
Allow: /index.php?option=com_xmap&view=xml&id=1
Allow: /images/
Allow: /templates/*.css
Allow: /templates/*.jsvAllow: /media/*.pngAllow: /media/*.js
Allow: /modules/*.css
Allow: /modules/*.js
Sitemap: http://site.ru/sitemap.xml
Популярные файлы robots.txt под задачи
Закрыть от индексации полностью сайт в robots.txt
User-agent: *
Disallow: /
Закрыть от индексации все страницы кроме главной в robots.txt
User-agent: *
Disallow: /
Allow: /$
Закрыть одну страницу в robots.txt
User-agent: *
Disallow: /URL # где URL ваша страница
Пример robots.txt для Яндекса
User-agent: Yandex
Disallow: /URL # где URL ваша страница
Пример robots.txt для Google
User-agent: Google
Disallow: /URL # где URL ваша страница
Пример robots.txt для всех поисковиков
User-agent: *
Disallow: /URL # где URL ваша страница
Популярные вопросы про файл robots.txt
Как создать файл robots txt для сайта в онлайн?
Для быстрого создания файла воспользуйтесь инструментом https://tools.discript.ru/robots-check/ он позволит быстро сгенерировать подходящий файл для вашего сайта.
Как проверить robots.txt онлайн?
Для быстрой проверки сайта Вы можете воспользоваться следующими инструментами:
- https://www.google.com/webmasters/tools/siteoverview?hl=ru
- http://webmaster.yandex.ru/robots.xml
Если Вам необходимо изучить файл robots конкурентов, то можете воспользоваться инструментом https://tools.discript.ru/robots-check/ или перейти по адресу site.ru/robots.txt, где site.ru сайт файл, которого ходите изучить.
Как проверить закрыт ли сайт от индексации?
Для быстрой проверки, закрыта ли страницы от индексации Вы можете воспользоваться инструментом https://tools.discript.ru/robots/, для этого достаточно указал URL, который хотите проверить.
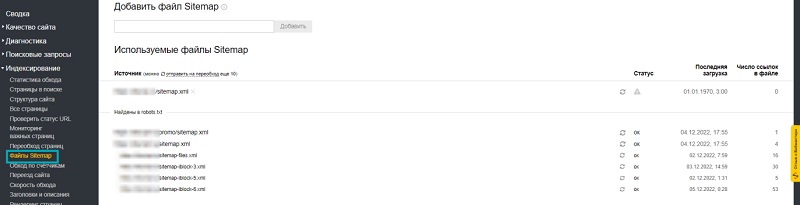
Что делать если «Нет используемых роботом файлов sitemap»?
Данная ошибка появляется в панели Яндекс Вебмастера. Чтобы помочь Яндексу найти файл sitemap, вы можете его указать в панели Вебмастера.
Или добавить в файле директиву sitemap, как это сделать читайте тут
Как проверить есть ли robots.txt на сайте?
Чтобы проверить есть ли на сайте файл robots.txt достаточно перейти по адресу site.ru/robots.txt, где site.ru сайт файл, которого ходите изучить. Если открылся файл robots.txt, то он присутствует на проверяемом сайте.
Как удалить цифры по маске в robots.txt?
User-agent: *
Disallow: *0
Disallow: *1
Disallow: *2
Disallow: *3
Disallow: *0
Disallow: *5
Disallow: *6
Disallow: *7
Disallow: *8
Disallow: *9
Как производить экранирование символов в robots.txt?
Спецификация robots.txt не допускает использования регулярных выражений. В url допустимы только * и &.
В заключение
Таким образом при работе с robots.txt необходимо знать:
- Правила составления и расположения файла;
- Функции отдельных директив и способы их применения;
- Рекомендации по закрытию определенных страниц;
- Инструменты для проверки robots.txt: http://tools.discript.ru/robots-check/, а также инструменты Яндекс и Google.
Важно помнить, что проверка robots.txt — один из первых этапов создания любого проекта, и от того, насколько точно она будет проведена, может зависеть конечный результат работы.
В следующей статье мы поговорим о терминологии, применяемой при работе над скоростью загрузки.
Что такое robots.txt

Robots.txt — это стандартный текстовый файл в кодировке UTF-8 с расширением .txt, который содержит директивы и инструкции индексирования сайта, его страниц или разделов. Он необходим для роботов поисковых систем. В статье расскажем, зачем он нужен, какие инструменты используются для его проверки и настройки под Яндекс и Google, а также представим рекомендации по созданию.
Это первый файл, к которому обращаются поисковые системы, чтобы определить, может ли проводиться индексация сайта. Файл располагается в корневой директории сайта. Разместить его можно через FTP-клиент. Файл должен быть доступен в браузере по ссылке вида site.ru/robots.txt. На него нужно смотреть в первую очередь, если на сайт “упал трафик”.
Рассмотрим наиболее простой пример содержимого robots.txt (кстати, в названии должен быть строго нижний регистр букв), которое позволяет поисковым системам индексировать все разделы сайта:
User-agent: *
Allow: /
Эта инструкция дословно говорит: роботы, которые читают данную инструкцию (User-agent: *), могут индексировать весь сайт (Allow: /).
Зачем он вообще необходим? Чтобы это понять, достаточно представить, как работает поисковый робот. Им по умолчанию приходится просматривать миллиарды страниц по всему интернету, а затем определить для каждой страницы запросы, которым они могут соответствовать. В конце они ранжируют общую массу в поисковой выдаче. Конечно, это задача не из легких. Для работы поисковых алгоритмов задействуются колоссальные ресурсы, которые, конечно, ограничены.
Если кроме страниц, которые содержат полезный контент и которые по задумке владельца сайта должны попадать в выдачу, роботу придется просматривать еще множество технических страниц, которые не представляют никакой ценности для пользователей, его ресурсы будут растрачиваться впустую. Лишь один сайт может генерировать тысячи страниц результатов поиска по сайту, повторяющихся страниц или таких страниц, которые не содержат контента вообще. А если этот объем масштабировать на всю сеть, то получатся огромные цифры и соответствующие ресурсы, которые придется тратить поисковикам.
Наличие огромного количества бесполезного контента на сайте может отрицательно сказаться на его представлении в поиске.
Помимо этого, существует такое понятие, как краулинговый бюджет. Условно говоря, это объем страниц, который может участвовать в поисковой выдаче от одного сайта. Этот объем, конечно, ограничен, хоть по мере роста проекта и повышения его качества краулинговый бюджет может увеличиваться. Главная мысль в том, в выдаче должны участвовать лишь страницы, которые содержат полезные записи, а весь технический «мусор» не должен засорять выдачу.
Зачем Robots.txt нужен для SEO?

Если на сайте нет robots.txt, то роботы из поисковых систем будут беспорядочно блуждать по всему сайту. Роботы могут попасть в корзину с мусором, после чего они «сделают вывод», что на сайте слишком грязно. А с помощью robots.txt можно скрыть определенные страницы от индексации. Его нужно создавать для каждого поддомена.
Правильно заполненный файл robots.txt с верной последовательностью позволит роботу создать представление, что на сайте всегда чисто и убрано. Важно регулярно проверять содержимое.
Где находится и как создать?
Файл robots.txt размещается в корневой директории сайта: путь к файлу robots станет таким: site.ru/robots.txt.
Принцип настройки и как редактировать. Техническая часть

После написания файла Robots его текст можно редактировать в процессе оптимизации ресурса, например, в Notepad. Делать это нужно в текстовом файле robots.txt с соблюдением правил и синтаксиса файла, но не в HTML редакторе. После редактирования на сайт можно выгрузить обновленную версию файла. Кстати, для определенны CMS есть специальные плагины и дополнения, которые дают возможность редактировать файл прямо в админ панели.
Подробнее рассмотрим список директив, используемые символы и принципы настройки.
User-Agent
Это обязательная директива, которая определяет, к какому роботу будут применяться прописанные ниже в файле правила. Иными словами, это обращение к конкретному роботу или всем поисковым ботам. Все файлы должны начинаться именно с этой строчки. Пустой эту строку оставлять нельзя. Регистр символов в значениях директивы User-agent (пользовательский агент) не принимается во внимание.
Disallow
Disallow. Наиболее распространенная директива, запрещающая индексировать определенные страницы или целые разделы веб-сайта. В этой строке можно использовать спец символы * и $. Точка с запятой не используются. Пробел в начале строки ставить можно, но не рекомендуется.
Что нужно исключить из индекса?
- В первую очередь роботу необходимо запретить включать в индекс любые дубли страниц. Доступ к странице должен осуществляться лишь по одному URL. Обращаясь к сайту, поисковый бот по каждому URL должен получить в ответ страницу строго с уникальным содержанием. Дубли нередко появляются у CMS в процессе создания страниц. Так, один и тот же документ можно найти по техническому домену в формате http:// site.ru/?p=391&preview=true и “человекопонятному” URL http:// site.ru/chto-takoe-seo. Часто дубли появляются и из-за динамических ссылок. Важно их все скрывать от индекса с помощью масок (писать каждую команду нужно с новой строки):
Disallow: /*?*
Disallow: /*%
Disallow: /index.php
Disallow: /*?page=
Disallow: /*&page=
2. Все страницы с неуникальным контентом, например, статьями, новостями, а также политикой конфиденциальности, картинками, изображениями и проч. Такие документы стоит скрыть от поисковых машин, прежде чем они начнут индексироваться.
3. Все страницы, которые используются при работе сценариев. К примеру, это те, где есть сообщения наподобие “Спасибо за ваш отзыв!”.
4. Страницы, которые включают индикаторы сессий. Для подобных страниц тоже рекомендуется использовать директиву Disallow с соответствующими символами. В строке указывается:
Disallow: *PHPSESSID=
Disallow: *session_id=
5. Все файлы движка управления сайтом. Это файлы шаблонов, администраторской панели, тем, баз и другие. Возможные исключения:
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
6. Бесполезные для пользователей страницы и разделы. К примеру, не имеющие какого-либо содержания, с неуникальным контентом, несуществующие и так далее. Их роботу видеть не стоит. Кроме этого, для робота Googlebot при необходимости можно заблокировать выдачу сайта в новостях через Googlebot-News, а через Googlebot-Image — запретить показ изображений в Гугл Картинках.
Рекомендуем держать файл robots.txt всегда в порядке и в чистоте, и тогда ваш сайт будет индексироваться значительно быстрее и лучше, а ранжироваться выше.
Запрет конкретного раздела сайта
User-agent: *
Disallow: /admin/
Запрет на сканирование определенного файла
User-agent: *
Disallow: /admin/my-embarrassing-photo.png
Полная блокировка доступа к хосту
User-agent: *
Disallow: /
Разрешить полный доступ
Разрешает полный доступ:
User-agent: *
Disallow:
Allow
С помощью такой директивы можно, напротив, допустить каталог или конкретный адрес для того, чтобы он индексировался. В некоторых случаях быстрее и легче запретить к сканированию весь сайт и с помощью строки Allow открыть роботу необходимые разделы.
User-agent: *#
Блокируем весь раздел /admin
Disallow: /admin#
Кроме файла /admin/css/style.css
Allow: /admin/css/style.css#
Открываем все файлы в папке /admin/js. Например:
# /admin/js/global.js
# /admin/js/ajax/update.js
Allow: /admin/js/
Директива Crawl-delay
Директива, которая не актуальна в случае Goolge, но очень полезна для работы с другими поисковиками, например, Яндекс или даже Yahoo..
С ее помощью можно замедлить сканирование, если сервер бывает перегружен. Она задает интервал времени для обхода страниц в секундах (актуально для Яндекса). Чем выше значение, тем медленнее краулер станет обходить страницы сайта.
User-agent: *
Crawl-delay: 5
Хотя Googlebot игнорирует подобные правила, настроить скорость сканирования можно в Google Search Console проекта.
Важно, что китайским Baidu тоже не учитывается наличие Crawl-delay в robots.txt, а Bing воспринимает команду как «временное окно», в рамках которого BingBot будет сканировать сайт лишь единожды.
Стоит учитывать: если установлено высокое значение Crawl-delay, самое главное — убедиться, что сайт своевременно индексируется. В сутках 86 400 секунд, при Crawl-delay: 30 будет просканировано менее 2880 страниц в день, и этот показатель не слишком велик для крупных сайтов.
Директива Clean-param
Директива Clean-param дает возможность запрещать поисковому роботу обход страниц с динамическими параметрами, контент которых не имеет отличий от основной страницы. Например, многие интернет-магазины используют параметры в url-адресах, которые отправляют данные по источникам сессий, в том числе персональные идентификаторы пользователей.
Чтобы поисковые роботы не заходили на данные страницы и лишний раз не создавали нагрузку на сервер, можно использовать директиву Clean-param, которая поможет оставить в выдаче только исходный документ.
Давайте рассмотрим использование данной директивы на примере. Например, что сайт собирает информацию по пользователям на страницах:
https:// site.ru/get_book/?userID=1&source=site_2&book_id=3
https:// site.ru/get_book/?userID=5&source=site_4&book_id=5
https:// site.ru/get_book/?userID=9&source=site_11&book_id=2
Параметр userID, который есть в каждом url-адресе, показывает персональный идентификатор пользователя, а параметр source показывает источник, из которого посетитель попал на сайт. По трем разным url-адресам пользователи видят один и тот же контент book_id=3. В этом случае нам необходимо использовать директиву Clean-param таким образом:
User-agent: Yandex
Clean-param: userID /books/get_book.pl
Clean-param: source /books/get_book.pl
Данные директивы позволяют поисковому роботу Яндекса свести все динамические параметры в единую страницу:
https:// site.ru/books/get_book.pl?&book_id=3
Если на сайте есть такая страница, то именно она станет индексироваться и участвовать в выдаче.
Главное зеркало сайта в robots.txt — Host

С марта 2018 года Яндекс отказался от директивы Host. Ее функции полностью перешли на раздел «Переезд сайта в Вебмастере» и 301-редирект.
Директива Host указывает поисковому роботу Яндекса на главное зеркало сайта. Если сайт был доступен сразу по нескольким разным URL адресам, например, с www и без www, требовалось настроить 301 редирект на главный URL адрес и указать его в директиве Host, поддержка Host прекращена.
Эта директива была полезна при установке SSL-сертификата и переезде сайта с http на https. В директиве Host адрес сайта при наличии SSL-сертификата указывался с https.
Директива Host указывалась в User-agent: Yandex только 1 раз. Например для нашего сайта это выглядело таким образом:
User-agent: Yandex
Host: https:// site.ru
В этом примере указано, что главным зеркалом сайта oparinseo.ru является ни www.oparinseo.ru, ни http://oparinseo.ru, а именно https://oparinseo.ru.
Для указания главного зеркала сайта в Google требуется использовать инструменты вебмастера в Google Search Console.
Комментарии в robots.txt
Комментарии в файле robots.txt можно оставлять после символа # — они будут игнорироваться поисковыми системами. Чаще всего они необходимы для обозначения причин открытия или закрытия для индексации определенных страниц, чтобы в будущем оптимизатор мог точно понять причины тех или иных правок в файле.
Один из примеров:
#Это файл robots.txt. Все, что прописывают в данной строке, роботы не прочтут
User-agent: Yandex #Правила для Яндекс-бота
Disallow: /pink #закрыл от индексации, т.к. на странице есть неуникальный контент
Карта сайта в robots.txt — Sitemap.xml
Директива Sitemap позволяет показать поисковому роботу путь на xml карту сайта. Этот файл очень важен для поисковых систем, так как при обходе сайта они в самом начале обращаются к нему. В этом файле представлена структура сайта со всем внутренними ссылками, датами создания страниц, приоритетами индексирования.
Пример robots.txt с указанием адреса карты сайта в строке:
User-agent: *
Sitemap: https:// site.ru/sitemal.xml
Благодаря наличию xml карты сайта представление сайта в поисковой выдаче улучшается. Она является стандартом, который должен использоваться на каждом сайте. Частота обновления и актуальность поддержания sitemap.xml сможет значительно увеличить скорость индексирования страниц, особенно у относительно молодого сайта.
Как проверить Robots.txt?
После того, как готовый файл robots.txt был загружен на сервер, обязательно необходима проверка его доступности, корректности и наличия ошибок в нем.
Как проверить robots.txt на сайте?
Если файл составлен правильно и загружен в корень сервера, то после загрузки он будет доступен по ссылке типа site.ru/robots.txt. Он является публичным, поэтому посмотреть и провести анализ robots.txt можно у любого сайта.
Как проверить robots.txt на наличие ошибок — доступные инструменты
Можно провести проверку robots.txt на наличие ошибок, используя для этой цели специальные инструменты Гугл и Яндекс:
- В панели Вебмастера Яндекс — https://webmaster.yandex.ru/tools/robotstxt/
- В Google Search Console — https://www.google.com/webmasters/tools/robots-tes…
Эти инструменты покажут все ошибки данного файла, предупредят об ограничениях в директивах и предложат провести проверку доступности страниц сайта после настройки robots.txt.
Частая ошибка Robots.txt
Обычной распространенной ошибкой является установка индивидуальных правил для User-Agent без дублирования инструкций Disallow.
Как мы уже выяснили, при указании директивы User-Agent соответствующий краулер будет следовать лишь тем правилам, что установлены именно для него, а остальные проигнорирует. Важно не забывать дублировать общие директивы для всех User-Agent.
Правильный robots.txt для WordPress

Внешний вид Robots.txt на платформе WordPress
Ниже представлен универсальный пример кода для файла robots.txt. Для каждого конкретного сайта его нужно менять или расширять, чтобы страницы могли проиндексироваться корректно.
В представленном варианте нет опасности запретить индексацию каких-либо файлов внутри ядра WordPress либо папки wp-content.
User-agent: *
# Нужно создать секцию правил для роботов. * означает для всех роботов. Чтобы указать секцию правил для отдельного робота, вместо * укажите его имя: GoogleBot (mediapartners-google), Yandex.
Disallow: /cgi-bin # Стандартная папка на хостинге.
Disallow: /wp-admin/ # Закрываем админку.
Disallow: /? # Все параметры запроса на главной.
Disallow: *?s= # Поиск.
Disallow: *&s= # Поиск.
Disallow: /search # Поиск.
Disallow: /author/ # Архив автора.
Disallow: */embed$ # Все встраивания. Символ $ — конец строки.
Disallow: */page/ # Все виды пагинации.
Disallow: */xmlrpc.php # Файл WordPress API
Disallow: *utm*= # Ссылки с utm-метками
Disallow: *openstat= # Ссылки с метками openstat
#
Одна или несколько ссылок на карту сайта (файл Sitemap). Это независимая
# директива и дублировать её для каждого User-agent не нужно. Например,
# Google XML Sitemap создает две карты сайта:
Sitemap: http:// example.com/sitemap.xml
Sitemap: http:// example.com/sitemap.xml.gz
Правильный robots.txt для Joomla

Внешний вид Robots.txt на платформе Joomla
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /tmp/
Sitemap: https:// site.ru/sitemap.xml
Здесь указаны другие названия директорий, однако суть остается одной: таким образом закрываются мусорные и служебные страницы, чтобы показать поисковым системам лишь то, что они должны увидеть
Правильный robots.txt для Tilda
Оба файла — роботс и карта сайта — генерируются Тильдой автоматически.
Чтобы просмотреть их, добавьте к вашему адресу сайта /robots.txt или /sitemap.xml, например:
http:// mysite.com/robots.txt
http:// mysite.com/sitemap.xml
Правда, единственный вариант внести кардинальные изменения в эти файлы для сайта на Тильде — экспортировать проект на собственных хостинг и произвести нужные изменения.
Правильный robots.txt для Bitrix

Внешний вид Robots.txt на платформе Bitrix
Код для Robots, который представлен ниже, является базовым, универсальным для любого сайта на Битриксе. В то же время важно понимать, что у каждого сайта могут быть свои индивидуальные особенности, и этот файл может потребоваться корректировать и дополнять в вашем конкретном случае. После этого его нужно сохранить.
User-agent: * # правила для всех роботов
Disallow: /cgi-bin # папка на хостинге
Disallow: /bitrix/ # папка с системными файлами битрикса
Disallow: *bitrix_*= # GET-запросы битрикса
Disallow: /local/ # папка с системными файлами битрикса
Disallow: /*index.php$ # дубли страниц index.php
Disallow: /auth/ # авторизацияDisallow: *auth= # авторизация
Disallow: /personal/ # личный кабинет
Disallow: *register= # регистрация
Disallow: *forgot_password= # забыли пароль
Disallow: *change_password= # изменить пароль
Disallow: *login= # логин
Disallow: *logout= # выход
Disallow: */search/ # поиск
Disallow: *action= # действия
Disallow: *print= # печать
Disallow: *?new=Y # новая страница
Disallow: *?edit= # редактирование
Disallow: *?preview= # предпросмотр
Disallow: *backurl= # трекбеки
Disallow: *back_url= # трекбеки
Disallow: *back_url_admin= # трекбеки
Disallow: *captcha # каптча
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: *?FILTER*= # здесь и ниже различные популярные параметры фильтров
Disallow: *?ei=
Disallow: *?p=
Disallow: *?q=
Disallow: *?tags=
Disallow: *B_ORDER=
Disallow: *BRAND=
Disallow: *CLEAR_CACHE=
Disallow: *ELEMENT_ID=
Disallow: *price_from=
Disallow: *price_to=
Disallow: *PROPERTY_TYPE=
Disallow: *PROPERTY_WIDTH=
Disallow: *PROPERTY_HEIGHT=
Disallow: *PROPERTY_DIA=
Disallow: *PROPERTY_OPENING_COUNT=
Disallow: *PROPERTY_SELL_TYPE=
Disallow: *PROPERTY_MAIN_TYPE=
Disallow: *PROPERTY_PRICE[*]=
Disallow: *S_LAST=
Disallow: *SECTION_ID=
Disallow: *SECTION[*]=
Disallow: *SHOWALL=
Disallow: *SHOW_ALL=
Disallow: *SHOWBY=
Disallow: *SORT=
Disallow: *SPHRASE_ID=
Disallow: *TYPE=
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Disallow: *from= # ссылки с метками from
Allow: */upload/ # открываем папку с файлами uploads
Allow: /bitrix/*.js # здесь и далее открываем для индексации скрипты
Allow: /bitrix/*.css
Allow: /local/*.js
Allow: /local/*.css
Allow: /local/*.jpg
Allow: /local/*.jpeg
Allow: /local/*.png
Allow: /local/*.gif
# Укажите один или несколько файлов Sitemap
Sitemap: http:// site.ru/sitemap.xml
Sitemap: http:// site.ru/sitemap.xml.gz
Robots.txt в Яндекс и Google

Многие оптимизаторы, делая только первые шаги в работе с robots.txt, задаются логичным вопросом о том, почему нельзя указать общий User-agent: * и не указывать роботу каждого поисковика — Яндекс и Google — одни и те же инструкции.
Все дело в том, что поисковая система Google более позитивно воспринимает директиву User-agent: Googlebot в файле robots, а Яндекс — отдельную директиву User-agent: Yandex.
Прописывая ключевые правила отдельно для Google и Яндекс, можно управлять индексацией страниц и разделов веб-ресурса посредством Robots. Кроме того, применение персональных User-agent, поможет запретить индексацию некоторых файлов Google, но при этом оставить их доступными для роботов Яндекса, и наоборот.
Максимально допустимый размер текстового документа robots составляет 32 КБ (если он больше, файл считается открытым и полностью разрешающим). Это позволяет почти любому сайту указать все необходимые для индексации инструкции в отдельных юзер-агентах для Google и Яндекс.. Поэтому лучше не проводить эксперименты и указывать правила, которые относятся к каждому поисковику.
Кстати, Googlebot-Mobile — робот, индексирующий сайты для мобильных устройств.
Правильно настроенный файл robots.txt может позитивно влиять на SEO-продвижение сайта в Яндекс и Google, улучшение позиций. Если вы хотите избавиться от “мусора” и навести порядок на сайте, улучшить его индексацию, в первую очередь нужно работать именно с robots.txt. И если самостоятельно справиться с этим из-за отсутствия опыта и достаточных знаний сложно, лучше доверить эту задачу SEO-специалисту.
Чтобы все нужные страницы попали в индекс поисковых систем и заняли позиции в топ-10 Яндекс и Google, необходимо обеспечить корректную индексацию страниц.
Все нужные страницы должны быть доступны для индексации, а служебные страницы, дубли, страницы с GET-параметрами и другие страницы, которые могут затруднять ранжирование сайта, должны быть исключены из индекса.
В этом вам поможет файл robots.txt.
Robots.txt – это стандарт исключений для поисковых роботов, который состоит из инструкций для поисковых роботов. Данные инструкции сообщают, какие страницы запрещены или разрешены для индексации. Это текстовый файл в кодировке UTF-8, который размещается в корневой папке сайта.
Сформировать файл robots.txt можно в любом текстовом редакторе.
Robots.txt позволяет управлять трафиком поисковых роботов. С помощью файла robots.txt можно исключить страницы из индекса, закрыв от индексации.
Файл robots.txt используется для исключения из индекса:
- Системных файлов
- Служебных папок
- Панели администратора
- Страниц фильтрации и сортировки
- Страницы с GET-параметрами
- Корзины
- Личного кабинета
- Форм регистрации
- Страниц, содержащих данные пользователей
- Прочих страниц, которые не несут полезной информации для пользователей
Также файл robots.txt может сообщать поисковым роботам, какие страницы необходимо проиндексировать. Открывающие директивы указываются в robots.txt в том случае, если какой-либо нужный документ находится в закрытом разделе.
Например, в robots.txt закрыта от индексации служебная папка /birtix/. При этом в данной папке находятся файлы изображений, которые необходимо проиндексировать, например /bitrix/upload/image.png.
В данном случае robots.txt будет содержать следующие директивы:
User-agent: *
Allow: /bitrix/upload/*.png
Disallow: /birtix/
obots.txt может содержать ссылку на xml-карту сайта. Это позволит поисковым роботам быстрее найти карту сайта и проиндексировать новые страницы, либо страницы, в которые были внесены изменения.
Также в файл robots.txt можно добавить директиву Clean-param, которая запрещает роботам Яндекса индексировать страницы с GET-параметрами (например, страницы с рекламными метками), при этом разрешает учитывать поведенческие факторы на данных страницах.
User-Agent — указывает имя поискового робота, для которого будут применяться следующие правила (например, Googlebot, Yandex).
После User-Agent необходимо поставить двоеточие, пробел и указать имя User-Agent.
Пример:
User-Agent: Googlebot
Disallow — закрывающая директива, которая указывает, какие страницы необходимо закрыть от индексации.
После Disallow необходимо поставить двоеточие, пробел и указать раздел или путь к странице, которую необходимо закрыть от индексации.
Пример:
Disallow: /catalog/
Allow — разрешающая директива, которая указывает страницы, которые необходимо проиндексировать.
Allow необходимо размещать для тех страниц, которые находятся в закрытой от индексации папке.
После Allow необходимо поставить двоеточие, пробел и указать раздел или путь к странице, которую необходимо открыть для индексации. Директива Allow для конкретного файла или страницы должна быть длиннее, чем закрывающая директива Disallow, которая закрывает раздел, где находится документ или страница.
Например, в robots.txt указана закрывающая директива Disallow: /bitrix/. При этом в папке /bitrix/upload/ лежат png изображения, которые необходимо открыть для индексации.
Для того, чтобы открыть png изображения для индексации, необходимо разместить следующие директивы:
В примере мы видим, что содержание открывающей директивы Allow длиннее, чем закрывающей директивы Disallow.
* — означает любую последовательность символов в пути страницы или любо обозначает всех User Agent. Символ * по умолчанию используется в конце строки, если не указывается иной символ.
Например:
User-Agent: * – директивы будут применяться для всех User-Agent.
Disallow: /*bitrix – закрывает все страницы, в URL которых содержится bitrix, вне зависимости от расположения.
Disallow: /bitrix* и Disallow: /bitrix – являются одинаковыми.
$ — обозначает конец строки и по умолчанию отменяет символ * в конце строки.
Например:
Disallow: /bitrix$
# — правило для размещения комментария. Данные правила игнорируются поисковыми роботами и служат в качестве подсказки для вебмастеров.
/ — указывает, что папка закрыта для сканирования.
Пример:
Disallow: /bitrix/ – закрыта вся папка /bitrix/. Соответственно все страницы, сложенные в эту папку, например /bitrix/upload/, будут закрыты от индексацииDisallow: / – закрывает весь сайт от индексации, так как / указывает на корневую папку сайта.
Sitemap — правило для указания ссылки на xml-карту сайта sitemap.xml.
Пример:
Sitemap: https://site.ru/sitemap.xml
Clean-param — директива для поисковых роботов Яндекса, которая сообщает о динамических параметрах в URL страницы, которые не меняют содержания страницы. Данная директива позволяет разрешить для индексации только основную страницу без дополнительных параметров в URL.
С помощью Clean-param можно закрыть страницы с рекламными метками (напр��мер, URL с utm-метками).
Пример:
Clean-param: utm_
Если необходимо закрыть несколько страницы с разными метками, необходимо перечислить метки через символ &.
Пример:
Clean-param: utm_& yclid_
Ранее в файле robots.txt размещали директивы Host — указывает на главное зеркало сайта, и Craw-delay — директива, устанавливающая минимальный период времени (в секундах) между посещениями страниц сайта поисковыми роботами. Данное правило использовалось в случаях, когда использовались слабые сервера, которые не выдерживали большой нагрузки. Сейчас такие сервера практически не используются.
Сейчас данные директивы считаются устаревшими и не используются при составлении robots.txt. При наличии в файле robots.txt таких директив можно сделать выводы, что файл давно не обновлялся.
Для составления файла robots.txt действуют общие правила:
- Название файла: robots
- Формат: текстовый
- Расширение: txt
- Кодировка: UTF-8
- Размер файла: не более 32 кб
- Код ответа сервера: 200 ОК
- Использование кириллицы: запрещено, за исключением текста комментариев
- Каждую команду прописывать с новой строки
- В начале строки не должно быть пробелов
- В конце директив не должно быть точки или точки с запятой
- В одной строке прописывается только одна директива
- Пустая директива Disallow: равнозначна Allow: / (разрешает индексировать вест сайт)
- Соблюдайте регистр символов (прописывайте имена файлов в том регистре, в котором они указаны в URL)
- Отсутствие robots.txt разрешает индексирование всех страниц сайта
User Agent – это идентификационная строка клиентского приложения, которая используется для приложений, поисковых роботов или пауков.
При посещении веб-страницы приложение отправляет веб-серверу текстовую строку с информацией о себе. Данная строка начинается с User-Agent и содержит название приложения, браузера, поискового робота или паука, и характеристики приложения или браузера (например, версию браузера).
В файле robots.txt User-Agent сообщает, для какого поискового робота предназначены приведенные ниже директивы.
Чаще всего в robots.txt указываются User-Agent
- Yandexbot
- Googlebot
- Все User-Agent обозначаются символом *
YandexBot – основной поисковый робот Яндекса, который занимается индексацией сайта.
YandexImages – робот, который индексирует изображения.
YandexMobileBot – собирает страницы для проверки их адаптивности под мобильные устройства.
YandexDirect – сканирует данные о материалах ресурсов-партнеров РСЯ.
YandexMetrika – поисковый робот сервиса Яндекс.Метрика.
YandexMarket – робот Яндекс.Маркета.
YandexCalendar – краулер Яндекс.Календаря.
YandexNews – робот, который индексирует Яндекс.Новости.
YandexScreenshotBot – делает скриншоты документов.
YandexMedia – робот, который индексирует мультимедийные данные.
YandexVideoParser – робот Яндекс.Видео.
YandexPagechecker – отображает микроразметку контента
YandexOntoDBAPI – паук объектного ответа, который скачивает изменяющиеся данные.
YandexAccessibilityBot – скачивает документы и проверяет доступность данных документов для пользователей.
YandexSearchShop – скачивает файлы формата Yandex Market Language, которые относятся к каталогам товаров.
YaDirectFetcher – собирает страницы с рекламой, с целью проверки доступности данных страниц для пользователей и анализа тематики.
YandexirectDyn – создает динамические баннеры.
Googlebot – основной поисковый робот Google, который индексирует страницы и проверяет их на адаптивность под мобильные устройства.
AdsBot-Google – анализирует рекламу и оценивает ее качество на страницах, оптимизированных под ПК.
AdsBot-Google-Mobile – анализирует рекламу и оценивает ее качество на страницах, оптимизированных под смартфоны.
AdsBot-Google-Mobile-Apps – анализирует рекламу в мобильных приложениях и оценивает ее качество.
Mediaparnters-Google – краулер маркетинговой сети Google AdSense.
APIs-Google – User-Agent пользователя APIs-Google, который проверяет push-уведомления.
Googlebot-Video – индексирует видеоконтент на страницах веб-сайтов.
Googlebot-Image – индексирует изображения.
Googlebot-News – сканирует страницы с новостями и добавляет их в Google Новости.
Ahrefs – SEO-инструмент для анализа ссылочной массы.
SEMrush – онлайн-сервис для оптимизации сайтов.
SEO Spider – SEO программа для сканирования сайта.
Serpstat – инструмент для развития SEO и рекламного контента.
Moz – робот SEO-инструмента, который используется для анализа сайта.
Чтобы удалить из поисковой выдачи Яндекса и Google весь сайт или отдельные разделы и страницы, необходимо закрыть их от индексации. Тогда страницы постепенно будут исключены из индекса и не будут отображаться в поиске.
Закрыть страницы от индексации можно с помощью файла robots.txt.
В поисковой выдаче должны находиться страницы с полезным для пользователей контентом. Страницы в поиске должны отвечать на вопросы пользователей.
Некоторые страницы сайта могут содержать служебную информацию, либо дублировать основные канонические страницы. Наличие таких страниц в индексе может негативно повлиять на ранжирование сайта.
От индексации необходимо закрывать следующие типы страниц:
- Служебные страницы и разделы
- Дубли страниц
- Страницы с GET-параметрами
- Страницы сортировки
- Страницы фильтров
- Страницы с динамическими параметрами в URL (например, страницы с рекламными метками)
- Страницы с результатами поиска по сайту
- Страницы, которые могут содержать данные о пользователях
- Страницы оформления заказа и корзины
- Личный кабинет
Также необходимо закрывать от индексации тестовые страницы или тестовую версию сайта, служебные поддомены или зеркала сайта на других доменах.
Необходимо указать User-Agent, для которого закрываем сайт.Чтобы закрыть сайт для всех User-Agent, указываем:
User-Agent: *
Если необходимо закрыть весь сайт только для одного или нескольких конкретных User-Agent, указываем имена роботов, например:
User-Agent: Yandexbot
User-Agent: Googlebot
Добавляем закрывающую директиву Disallow и закрываем всю корневую папку:
User-Agent: *
Disallow: /
Если необходимо закрыть сайт для нескольких конкретных User-Agent, указываем всех User-Agent:
User-Agent: Googlebot
Disallow: /
User-Agent: Ahrefs
Disallow: /
Если необходимо закрыть сайт от индексации для всех User-Agent за исключением одного или нескольких User-Agent, необходимо добавить открывающую директиву Allow для User-Agent, для которого сайт будет доступен для индексации:
User-Agent: *
Disallow: /
User-Agent: Yandexbot
Allow: /
С помощью данной инструкции можно закрыть весь сайт от индексации и исключить все страницы сайта из поисковой выдачи.
Чтобы закрыть от индексации страницу или раздел сайта, необходимо следовать приведенным выше правилам, но вместо корневой папки, указать путь к странице или разделу, который необходимо закрыть.
Если необходимо закрыть весь раздел, указываем полностью папку данного раздела:
User-Agent: *
Disallow: /bitrix/
Таким образом мы закрываем от индексации всю папку /bitrix/ и все страницы, которые вложены в данный раздел, например папку /bitrix/upload/.
Директива без / в конце будет равнозначна директиве с /, например Disallow: /bitrix будет работать также, как и Disallow: /bitrix/. Соответственно аналогично работает символ *.
Все приведенные ниже директивы будут закрывать все страницы, вложенные в раздел /bitrix/:
Disallow: /bitrix
Disallow: /bitrix/
Disallow: /bitrix*
Disallow: /bitrix/*
Если закрыть для индексации необходимо только папку /bitrix/, необходимо добавить в конце пути символ $.
User-Agent: *
Disallow: /bitrix/$
В таком случае папка /bitrix/ будет закрыта, а все вложенные страницы в раздел /bitrix/ будут доступны для индексации, например страница /bitrix/upload/.
Если необходимо закрыть несколько разных страниц, которые содержат одинаковый параметр в URL, необходимо использовать символ * перед указанием общего параметра:
Таким образом можно закрыть страницы от индексации и исключить страницы их поисковой выдачи Яндекса и Google.
Clean-param — директива robots.txt, поддерживаемая роботами Яндекса. Clean-param позволяет сообщать о динамических параметрах, которые присутствуют в URL-адресах страниц (например, рекламные метки).
Директива Clean-param нужна для избежания возникновения дублей страниц. Наличие дублей страниц может негативно сказаться на индексации и ранжировании сайта в поисковых системах.
Кроме того, дубли страниц будут расходовать краулинговый бюджет, что может замедлить индексацию других страниц сайта.
Например, на сайте присутствует страница категории каталога:
https://site.ru/catalog/category/
Данная страница https://site.ru/catalog/category/ может иметь рекламные метки, например:
https://site.ru/catalog/category/?utm_source=yandex
Такие метки позволяют отслеживать переходы по рекламе и упрощать аналитику. При этом страницы с рекламными метками являются дублями канонической страницы https://site.ru/catalog/category/.
С помощью Clean-param мы можем закрыть от индексации дубли страниц (страницы с рекламными метками), указав Clean-param со следующим содержанием:
Clean-param: utm_
Указание такой директивы запретит индексировать Яндексу все страницы сайта, которые содержат в URL utm-метки.
Сайт может иметь несколько рекламных источников, в связи с чем на разных страницах могут быть указаны различные метки в URL, например:
- utm_source
- utm_medium
- utm_campaign
- utm_term
- utm_referrer
- cm_id
- from
- yclid
- gclid
- _openstat
- k50id
Чтобы закрыть страницы со всеми видами меток, необходимо указать в Clean-param все метки через символ &.
Пример:
Clean-param: utm_&k50id&cm_id&from&yclid&gclid&_openstat
В отличие от закрывающей директивы Disallow, Clean-param позволяет передавать основной канонической странице накопленные метрики и поведенческие факторы, о чем сообщается в Яндекс Справке.
В большинстве случаев использовать Clean-param не нужно, так как дубли страниц, сортировка и другие GET-параметры закрываются запрещающими директивами Disallow.
Директива Clean-param в robots.txt будет полезна сайтам с большим объемом рекламируемых страниц и рекламных источников.
Использование Clean-param позволит не индексировать страницы с рекламными метками, при этом поведенческие факторы с данных страниц будут учитываться Яндексом, о чем сообщает сам Яндекс в своей документации.
- В файле robots.txt указ��вается директива Clean-param: по аналогии с директивами Disallow и Allow
- Далее идет перечисление динамических параметров, которые влияют на индексацию сайта
- Если таких параметров несколько, они перечисляются через амперсанд – &
- При указании параметров необходимо учитывать регистр символов
- Длина директивы Clean-param ограничивается 500 символами (если объем директивы превышает 500 символов, можно указать второй Clean-param, либо оптимизировать текущий)
Для примера рассмотрим страницы разными UTM-метками:
https://www.site.ru/category/name-1/?utm_medium
https://www.site.ru/category/name-2/?utm_source
https://www.site.ru/category/name-3/?utm_campaign
Чтобы закрыть данные страницы от индексации, необходимо прописать следующую директиву:
Clean-param: utm_
Если URL страниц содержат разные рекламные метки, например:
https://www.site.ru/category/name-1/?yclid
https://www.site.ru/category/name-2/?gclid
https://www.site.ru/category/name-3/?utm_source
https://www.site.ru/category/name-4/?utm_campaign
Необходимо сформировать директиву Clean-param следующим образом:
Clean-param: utm_&gclid&yclid
Файл robots.txt позволит улучшить индексацию вашего сайта и исключить из индекса лишние страницы, которые могут негативно сказаться на ранжировании сайта.
Чтобы файл robots.txt эффективно решал свою задачу, необходимо придерживаться правил составления robots.txt и соблюдать синтаксис файла.
Ниже приведена пошаговая инструкция по составлению файла robots.txt.
В первой строке файла robots.txt необходимо указать User-Agent, для которого будут прописаны правила. Пропишите User-Agent: и добавьте название поискового робота.
Пример:
User-Agent: Googlebot
Если на правила в файле robots.txt необходимо реагировать всем роботам, укажите всех User-Agent с помощью символа *:
User-Agent: *
После указания User-Agent необходимо разместить запрещающие директивы Disallow.
Закройте от индексации страницы, которые не содержат полезной информации для пользователей, например:
- Служебные файлы и папки
- Страницы результатов поиска
- Страницы сортировки
- Страницы фильтров (в некоторых случаях)
- Страницы с результатами поиска по сайту
- Личный кабинет
- Корзину
- Страницы, которые содержат данные о пользователях
- Страницы оформления заказа
Пример:
#сообщаем, что правило в robots.txt действуют для всех роботов
User-agent: *
#закрываем всю папку со служебными файлами
Disallow: /bitrix/
#закрываем сортировку на всех страницах сайта
Disallow: /*sort=
#закрываем страницы результатов поиска с любым значением после =
Disallow: /*search=
#закрываем корзину
Disallow: /basket/
#закрываем страницы оформления заказа
Disallow: /order
#закрываем личный кабинет
Disallow: /lk/
#закрываем страницы фильтров в каталоге
Disallow: /filter/
Если в ранее закрытых папках находятся страницы или файлы, которые необходимо проиндексировать, например изображения, PDF документы, необходимо добавить разрешающие директивы.
Также необходимо открыть для индексации скрипты и стили.
Пример:
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
Важно! Разрешающие директивы должны быть длиннее запрещающих.
User-agent: *
#разрешаем индексировать изображения и PDF документы, которые лежат в закрытой папке /bitrix/upload/
Allow: /bitrix/upload/*.png
Allow: /bitrix/upload/*.jpg
Allow: /bitrix/upload/*.jpeg
Allow: /bitrix/upload/*.pdf
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
#далее идут ранее составленные закрывающие директивы
Disallow: /bitrix/
Disallow: /*sort=
Disallow: /*search=
Disallow: /basket/
Disallow: /order
Disallow: /lk/
Disallow: /filter
В правилах Clean-param необходимо указать динамические параметры, которые не влияют на содержание страницы, например, рекламные метки.
Пример:
Clean-param: utm_&k50id&cm_id&from&yclid&gclid&_openstat
Правило Clean-param действует только для Яндекса, в связи с этим необходимо указать User-Agent для которого предназначено данное правило:
User-agent: *
Allow: /bitrix/upload/*.png
Allow: /bitrix/upload/*.jpg
Allow: /bitrix/upload/*.jpeg
Allow: /bitrix/upload/*.pdf
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
Disallow: /bitrix/
Disallow: /*sort=
Disallow: /*search=
Disallow: /basket/
Disallow: /order
Disallow: /lk/
Disallow: /filter/
User-agent: Yandex
Allow: /bitrix/upload/*.png
Allow: /bitrix/upload/*.jpg
Allow: /bitrix/upload/*.jpeg
Allow: /bitrix/upload/*.pdf
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
Disallow: /bitrix/
Disallow: /*sort=
Disallow: /*search=
Disallow: /basket/
Disallow: /order
Disallow: /lk/
Disallow: /filter/
Clean-param: utm_&k50id&cm_id&from&yclid&gclid&_openstat
Правило Clean-param действует для поисковой системы Яндекс.
Чтобы страницы с динамическими параметрами не индексировались Google, необходимо закрыть от индексации страницы с метками, указав запрещающие директивы для всех остальных User-Agen.
Пример:
User-agent: *
Allow: /bitrix/upload/*.png
Allow: /bitrix/upload/*.jpg
Allow: /bitrix/upload/*.jpeg
Allow: /bitrix/upload/*.pdf
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
Disallow: /bitrix/
Disallow: /*sort=
Disallow: /*search=
Disallow: /basket/
Disallow: /order
Disallow: /lk/
Disallow: /filter/
Disallow: /*utm_
Disallow: /*k50id
Disallow: /*cm_id
Disallow: /*from
Disallow: /*yclid
Disallow: /*gclid
Disallow: /*_openstat
User-agent: Yandex
Allow: /bitrix/upload/*.png
Allow: /bitrix/upload/*.jpg
Allow: /bitrix/upload/*.jpeg
Allow: /bitrix/upload/*.pdf
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
Disallow: /bitrix/
Disallow: /*sort=
Disallow: /*search=
Disallow: /basket/
Disallow: /order
Disallow: /lk/
Disallow: /filter/
Clean-param: utm_&k50id&cm_id&from&yclid&gclid&_openstat
В файле robots.txt можно указать путь к xml-карте сайта. Это позволит ускорить индексацию новых страниц и страниц, на которые были внесены изменения.
User-agent: *
Allow: /bitrix/upload/*.png
Allow: /bitrix/upload/*.jpg
Allow: /bitrix/upload/*.jpeg
Allow: /bitrix/upload/*.pdf
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
Disallow: /bitrix/
Disallow: /*sort=
Disallow: /*search=
Disallow: /basket/
Disallow: /order
Disallow: /lk/
Disallow: /filter/
Disallow: /*utm_
Disallow: /*k50id
Disallow: /*cm_id
Disallow: /*from
Disallow: /*yclid
Disallow: /*gclid
Disallow: /*_openstat
Sitemap: https://site.ru/sitemap.xml
User-agent: Yandex
Allow: /bitrix/upload/*.png
Allow: /bitrix/upload/*.jpg
Allow: /bitrix/upload/*.jpeg
Allow: /bitrix/upload/*.pdf
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
Disallow: /bitrix/
Disallow: /*sort=
Disallow: /*search=
Disallow: /basket/
Disallow: /order
Disallow: /lk/
Disallow: /filter/
Clean-param: utm_&k50id&cm_id&from&yclid&gclid&_openstat
Sitemap: https://site.ru/sitemap.xml
Техническую проверку сайта рекомендуется начинать проверять именно с файла robots.txt.
Настройка индексации сайта – один из важнейших этапов в SEO-продвижении сайта. С помощью правильной настройки файла robots.txt можно управлять индексацией сайта и исключить из индекса страницы, которые могут негативно сказаться на ранжировании сайта.
Файл robots.txt позволяет управлять индексацией сайта. Правильно составленный robots.txt позволит убрать из индекса лишние страницы, которые могут помещать ранжированию сайта.
При этом поисковые системы Яндекс и Google предъявляют разные требования к составлению файла robots.txt.
В связи с этим необходимо проверять robots.txt на соответствия требования поисковых систем отдельно для Яндекса и Google.
Если несколько инструментов для проверки robots.txt.
Для проверки robots.txt необходимо авторизоваться в Яндексе и открыть инструмент для проверки robots.txt.
Введите проверяемый сайт и добавьте ваш вариант robots.txt в поле «Исходный код файла robots.txt». Сервис покажет результаты проверки и сообщит о наличии или отсутствии ошибок.
Важно провести проверку доступности основных продвигаемых типов страниц.
Добавьте в поле «Разрешены ли URL» ссылки на основные продвигаемые страницы и страницы, которые должны быть закрыты от индексации. Сервис покажет доступность страницы. Если нужные страницы не доступны для индексации или наоборот, служебные страницы не закрыты – проверьте корректность составления директив файла robots.txt
В старой версии Google Search Console был инструмент для проверки файла robots.txt. Однако в текущей версии панели вебмастера в Google такой инструмент отсутствует.
Вероятнее всего это связано с тем, что файл robots.txt не работает в поисковой системе Google для закрытия.
Чтобы закрыть страницы от индексации в Google, необходимо прописать на странице тег noindex, либо закрыть страницу обязательной авторизацией, о чем сообщает сам Google в своей документации.
Для исключения страницы из индекса Google можно использовать инструмент «Удаления» в Google Search Console.
При наличии ошибок в файле robots.txt ненужные страницы могут попасть в индекс поисковых систем, либо наоборот — важные страницы не будут проиндексированы. Это может негативно сказаться на ранжировании сайта.
Разберем частые ошибки файла robots.txt.
Файл robots.txt должен находится в корневой папке сайта и быть доступным по адресу корневой папки и /robots.txt.
Пример:
https://site.ru/robots.txt
Если файл robots.txt будет размещен по другому адресу, поисковые системы не будут учитывать содержимое файла.
Закрытие от индексации скриптов и стилей может вызвать проблемы, часть контента может не проиндексироваться, либо проиндексироваться не в полном объеме.
Это негативно скажется на релевантности страницы и, соответственно, ранжировании сайта в поисковых системах.
Если в robots.txt закрыты служебные папки, в которых содержатся стили и скрипты, необходимо отдельно прописать открывающие директивы для скриптов и стилей.
Пример:
Allow: /bitrix/upload/*.js
Allow: /bitrix/upload/*.css
Disallow: /bitrix/
Отсутствие sitemap.xml в robots.txt не является ошибкой – robots.txt будет корректно выполнять свои функции без ссылки на карту сайта. Однако наличие карты сайта в robots.txt может ускорить индексацию сайта.
Если директивы или User-Agent прописаны в robots.txt с ошибкой, поисковые роботы проигнорируют данные директивы, либо весь robots.txt (если ошибка в указании User-Agent).
Перед размещение файла robots.txt на сайте необходимо проверить файл на наличие ошибок и проанализировать, все ли необходимые страницы индексируются или не индексируется в соответствии с указанными правилами.
Гайд по файлу robots.txt – составляем правильный robots.txt самостоятельно
Robots.txt – это текстовый файл, расположенный в корневой папке сайта, содержащий в себе набор инструкций по обходу страниц сайта для роботов поисковых систем. В данной статье мы рассмотрим, какие директивы и спецсимволы используются, расскажем, как закрыть от индексации страницы сайта, составить данный файл правильно, приведем несколько шаблонов robots.txt для популярных CMS.
Для чего нужен файл
Роботы-краулеры поисковых систем перед посещением страницы обращаются к данному файлу, проверяя, доступна данная страница или нет. В файле содержатся все инструкции для роботов при сканировании сайта (индексация, запрет индексации, «склейка» параметров для Яндекса, расположение карты сайта. При запрете индексации поисковые системы не проиндексируют страницу. Это позволяет закрыть от индексации.
Именно по ключевикам поисковые системы определяют:
малоценные страницы для пользователя и др.
Корректной настройке данного файла следует уделять внимание, т.к. при наличии ошибок в данном файле страницы, разделы или весь сайт может оказаться закрытым от индексации.
Стоит понимать что данный файл является «рекомендательным», а не набором обязательных требований. Например, в Google Search Console вы можете встретить ошибку: «Проиндексировано, несмотря на блокировку в файле robots.txt».
В данном случае роботы поисковой системы могут индексировать страницы сайта, имеющие ссылки с внешних источников.

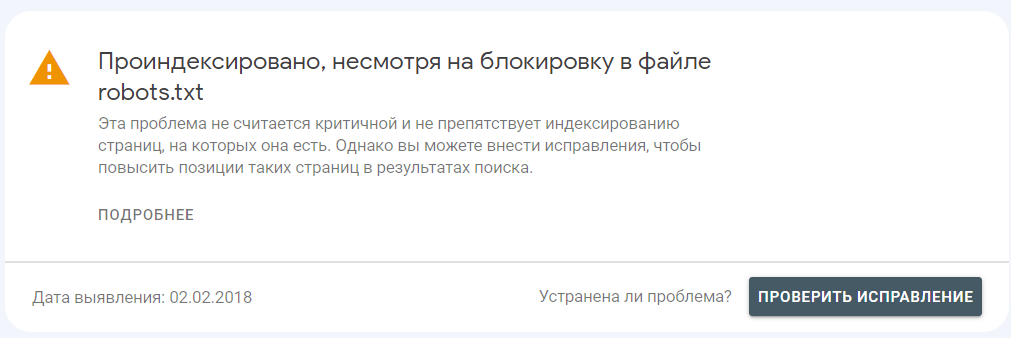
Источник developers.google.com
В случае если вам необходимо достоверно закрыть страницу от индексации в Google, требуется вместо запрета в роботсе использовать мета-тег robots в коде страницы (при запрете индексации в robots.txt робот может не просканировать данный тег). В разделе <head> HTML-кода страницы необходимо добавить мета-тег robots с значениями атрибута content = «noindex, nofollow»:
<meta name="robots" content="noindex, nofollow"/>Требования к файлу robots.txt
Название: только «robots.txt» в строчном регистре.
Размещение: только в корневом каталоге, например https://skobeeff.com/robots.txt (для поддоменов основного сайта – в корневых каталогах поддоменов, например https://seo.skobeeff.com/robots.txt)
Отклик: ссылка на файл должна отдавать 200 отклик сервера
Количество: в единственном экземпляре
Язык: латиница (за исключением #комментариев), если сайт имеет кириллические URL, необходимо конвертировать их в Punycode (кириллический адрес – xn-- -8sbmbdnaabkfeka6elki7h)
Порядок: каждая директива должна начинаться с новой строки
Директивы файла robots.txt
Определяет поискового робота, к которому относятся правила в группе
Запрещает индексирование разделов или отдельных страниц
Allow Разрешает индексирование разделов или отдельных страниц
Указывает расположение xml файла sitemap
Указывает роботу не индексировать параметрические страницы. Накопленные показатели передаются основному url/
(только Яндекс)
Неактуальная директива. Указывает основное зеркало сайта. Рекомендуется использовать 301 редирект.
(только Яндекс)
Неактуальная директива. Задает роботу скорость обхода сайта. Рекомендуется использовать настройку скорости обхода в Яндекс Вебмастере.
(только Яндекс)
Директива User-agent
Всего присутствует большое количество различных ботов поисковых систем и ботов различных приложений. Но в абсолютном большинстве случаев для настройки индексации сайта поисковыми системами рекомендуется использовать основные директивы. Также бытует мнение, что с помощью файла robots.txt можно блокировать ботов сторонних краулеров (например, AhrefsBot, SemrushBot). Но данные боты игнорируют файл robots.txt и такая блокировка бесполезна – эффективно блокировать их в файле .htaccess/
Все поисковые роботы Яндекса
Все поисковые роботы Google
Это обязательная директива, указывающая, для каких поисковых роботов будут применяться основные правила, написание под этой директивой – до следующей (за исключением Clean-param и Sitemap, являющихся межсекционными).
# Запрещаем индексацию для всех роботов, кроме Яндекса и Google:
User-agent: *
Disallow: /
# Задаем отдельные правила для робота Яндекса
User-agent: Yandex #
Disallow: /bitrix/
Disallow: /admin/
Clean-param: utm&from
# Задаем отдельные правила для робота Google
User-agent: Googlebot #
Disallow: /*?utm*
Disallow: /*&utm*
Disallow: /*?from*
Disallow: /*&from*конфиденциальные страницы;
параметрические страницы (например, с utm-метками);
страницы поиска по сайту;
Директива Disallow
Disallow – основная директива, запрещающая сканирование: сайта, раздела, отдельной страницы. В данной директиве чаще всего закрываются:
В данном правиле после знака слэша (/) указывается часть URL, на который нужно установить ограничения. Пустое правило разрешает индексировать весь сайт, только слеш (/) запрещает сканировать весь сайт (данное правило рекомендуется использовать для тестовой версии сайта).
Пример использования разных правил для роботов
User-agent: *
Disallow: # разрешаем все
User-agent: *
Disallow: / # запрещаем индексировать сайт
User-agent: *
Disallow: /razdel/ # запрещаем индексировать страницы, в адресе которых есть /razdel/
User-agent: *
Disallow: /razdel/odna-stranica.html #запрещаем индексировать только одну Существует ошибочное мнение, что наличие или отсутствие в конце слеша (/) влияет на закрытие раздела или только страницы. По умолчанию в конце каждого правила поисковые системы (например, Яндекс) считают, что находится неявный символ «*» (если не указано обратное).
Пример использования разных правил для роботов
Пример проверки данного утверждения в инструменте Яндекс.Вебмастер
Директива Allow
Allow – директива, разрешающая индексирование, применяется для прописывания исключений из директивы Disallow. Данное правило также поддерживает операторы «*» и «$».
Возвращаясь к нашему сайту из примера выше, добавим еще одну страницу (…/esche-odna-stranica.html). Допустим, нам нужно открыть только одну страницу, правила в роботс будут следующими:
User-agent: *
Disallow: /razdel/
Allow: /razdel/odna-stranica.htmlВ результате проверки получим доступной только необходимую нам страницу:
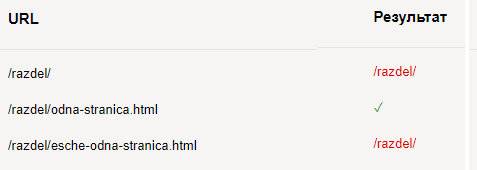
Наиболее часто это используется для разрешения индексации изображений, файлов с CSS и JS в CMS (файлы располагаются в служебных разделах сайта), пример для CMS 1С-Битрикс:
User-Agent: *
Disallow: /bitrix/ # Закрываем служебный раздел
Disallow: /admin/ # Закрываем служебный раздел
Disallow: /upload/ # Закрываем служебный раздел
Allow: */bitrix/*css # Открываем файлы стилей
Allow: */bitrix/*js # Открываем файлы JavaScript
Allow: */upload/*.jpg # Открываем файлы изображений в формате .jpg
Allow: */upload/*.jpeg # Открываем файлы изображений в формате .jpegДиректива Sitemap
Sitemap содержит в себе ссылку на xml карту(-ы) сайта, необязательная директива – если не используете sitemap.xml, добавлять правило не нужно.
Требования: в данном правиле каждый URL с новой строки, рекомендуется указывать абсолютные URL (полный адрес). Является межсекционным правилом – достаточно указать один раз в файле, без привязки к юзер-агентам, роботы обработают независимо от месторасположения (чаще всего для удобства размещают снизу остальных правил через пустую строку).

Sitemap: https://example.com/sitemap1.xml
Sitemap: https://example.com/sitemap2.xml
Sitemap: https://example.com/sitemap3.xmlидентификаторы сессий и пользователей;
параметры сортировок товаров и многое другое.
Директива Clean-param
Clean-param (только для Яндекса) – директива, позволяющая передать роботу динамические параметры страницы (GET-параметры) с одинаковым контентом, например:
Подобные параметрические страницы создают множество дублей основной страницы, мешающие ранжированию страницы в поиске. При использовании данной директивы характеристики пользователей с параметрических страниц будут передаваться основной, непараметрической странице, что при текущем влиянии поведенческих факторов в Яндексе явно выделяет преимущество использования Clean-param вместо закрытия с помощью Disallow. Также краулеры при обходе не будут сканировать URL с параметрами, что снизит нагрузку на сервер и позволит оптимизировать краулинговый бюджет сайта (метрика, определяющая квоту обхода страниц сайта при посещении роботом).
Поисковая система предлагает использовать синтаксис:
Clean-param: p0[&p1&p2&..&pn] [path]
p - параметр;
path - префикс url.
Пример:
Clean-param: abc /forum/showthread.php
Clean-param: sid&sort /forum/*.php
Clean-param: someTrash&otherTrash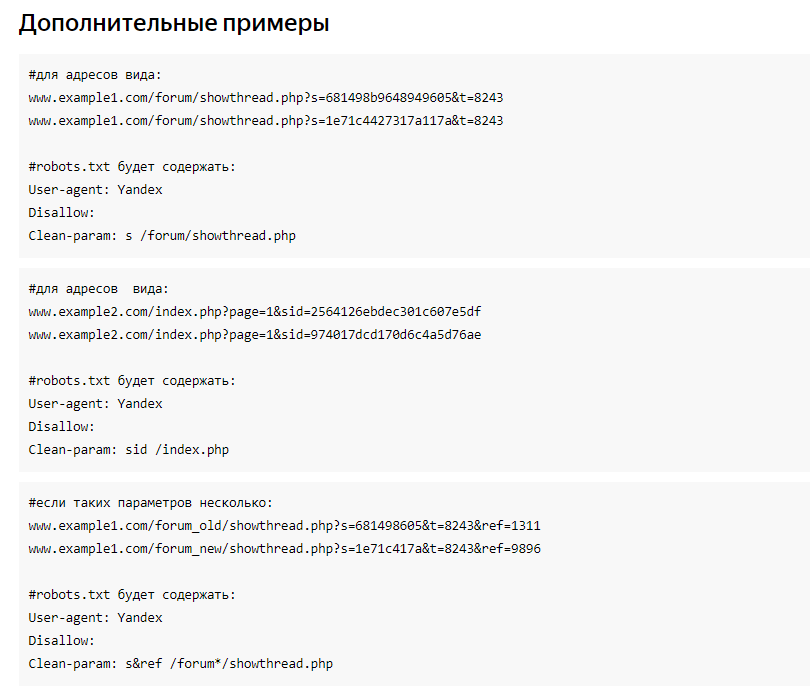
В настоящее время доступен более удобный и компактный способ добавления параметров, который в абсолютном большинстве случаев полноценно выполняет свои функции, а именно перечисление параметров в одной строке через амперсанд «&» (до 500 символов в строке).
Clean-param: openstat&utm&from&gclid&yclid&ymclid&tid&cm_id
Для проработки параметром можно использовать Яндекс.Метрику, выбираете отчет:
Отчет – Содержание – По параметрам URL
Далее изменяете группировки на:
«Параметр URL» и «Путь (полный) страницы»
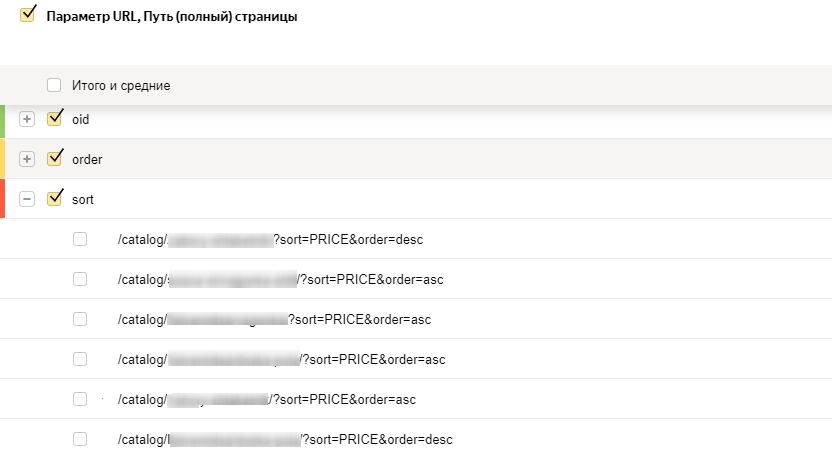
В таблице отчета указывается параметр и URL с данным параметром:
Далее в инструменте Вебмастера Анализ robots.txt вы можете проверить правильность работы данной директивы, добавив URL из отчета метрики. При корректном заполнении в результатах проверки добавляется столбец «URL после учета Clean-Param» с адресом без параметров (если там присутствуют параметры, добавьте их тоже в Clean-Param)

В Google для работы с параметрическими страницами до недавнего времени использовался инструмент «Параметры URL» в Google Search Console, но данный инструмент в настоящее время отключен и, по заверениям от поисковой системы, «в дальнейшем вам не нужно будет ничего делать для определения функции параметров URL на вашем сайте, поисковые роботы Google будут работать с параметрами URL автоматически».
Но если в индексе будут присутствовать подобные URL, рекомендуем закрыть их в
Disallow.
Спецсимволы robots.txt («*» «$» «#»)
В файле robots.txt используются символы:
Подразумевает любое количество символов после знака
Указывает окончание строки (противоположность «*»)
Разметка комментариев в файле, после данного символа роботы не обрабатывают содержимое строки, можно использовать кириллицу
Символ * – данный символ используется для сокращения правил и составления регулярных выражений, упрощающих работы.
Рассмотрим пример из битрикса, который уже приводили выше:
По умолчанию поисковые системы в конце каждого правила подразумевают неявную «*»
User-Agent: *
Disallow: /bitrix/ # Закрываем служебный раздел
Disallow: /admin/ # Закрываем служебный раздел
Disallow: /upload/ # Закрываем служебный раздел
Allow: */bitrix/*css # Открываем файлы стилей
Allow: */bitrix/*js # Открываем файлы JavaScript
Allow: */upload/*.jpg # Открываем файлы изображений в формате .jpg
Allow: */upload/*.jpeg # Открываем файлы изображений в формате .jpegВ данном примере правило: */upload/*.jpg распространяется для всех файлов формата .jpg, расположенных в разделе */upload/*
При этом данный раздел выделен с обеих сторон символом *, что означает, что до данного раздела может быть любая вложенность (количество папок), после тоже любое количество папок и любые названия файла, но имеющие вхождение .jpg в URL.
При этом в данном случае не обязательно формат является окончанием файла (неявная *).
С помощью данного синтаксиса можно упростить заполнение файла. Допустим, нам нужно закрыть страницу /nenuznaya-stranica/, которая размещена по адресу:
https://example.com/catalog/razdel1/razdel1-1/podrazel-razdel1/nenuznaya-stranica/
User-Agent: *
# закрываем без *:
Disallow: /catalog/razdel1/razdel1-1/podrazel-razdel1/nenuznaya-stranica/
# закрываем с помощью *:
Disallow: */nenuznaya-stranica/Символ $ указывает окончание строки, выполняя противоположную функцию символу «*».
Пример применения: на сайте из-за ошибок формируются страницы со знаком вопроса на конце URL, нам нужно закрыть подобные страницы, но не закрыть другие страницы, формирующиеся методом GET. В таком случае поможет правило:
User-agent: *
Disallow: /*?$ #действует только на страницы с ? в конце адреса Также, если нам нужно закрыть весь раздел с отзывами (при генерации для каждого отзыва отдельного адреса), но при этом оставить для индексации листинг отзывов, поможет правило
User-Agent: *
Disallow: /feedback/* # закрываем все
Allow: /feedback/$ # добавляем исключение для одной страницыСимвол # означает комментарии в строке, данные комментарии не воспринимаются поисковыми системами, может быть использована кириллица. Пример:
User-Agent: *
Disallow: / # Продам гараж Инструменты для проверки и составления файла robots.txt
Для проверки корректности и составления robots.txt в сети представлено много решений, мы рассмотрим стандартные инструменты Анализ robots.txt в Вебмастере Яндекса, Инструмент проверки файла robots.txt в Google Search Console.
Инструмент Яндекса
Анализ robots.txt в Вебмастере Яндекса позволяет загрузить действующий файл, отредактировать, проверить на ошибки синтаксиса, проверить действие для отдельных URL, проверить работу директивы Clean-param.
Для работы добавьте файл (или, если вы залогинены под аккаунтом с доступом к Вебмастеру, роботс подгрузится автоматически).
(a) зеленая галочка – доступен для индексации;
(b) красный шрифт с правилом из роботса – недоступен с указанием правила.
После загрузки файла в данном инструменте доступны три поля:
1. окно работы с robots.txt;
2. проверка на ошибки (при наличии укажет строку с ошибкой);
3. проверка URL – в данном файле вы можете добавить необходимые адреса для проверки, по результатам проверки:
Инструмент Google
Инструмент проверки файла robots.txt в Google Search Console доступен для проверки только при входе под аккаунтом с правами доступа в консоль сайта.
1. выбираете сайт, на котором нужно проверить robots.txt;
2. изменяете при необходимости правила;
3. в окне ниже можно проверить, как срабатывают правила для конкретного адреса:

Шаблон robots.txt для сайтов на Bitrix :
Пример правильного шаблона robots.txt для CMS
Ниже приведены примеры базового наполнения файлов robots.txt для сайтов на 1С-Битрикс и Вордпресс, но следует понимать, что данные настройки базовые и для реального сайта будут необходимы свои специфические директивы. Если вы планируете использовать данные шаблоны, рекомендуем проверить корректность работы на вашем сайте.
User-agent: *
Disallow: /auth*
Disallow: /basket*
Disallow: /order*
Disallow: /personal/
Disallow: /search/
Disallow: /test/
Disallow: /ajax/
Disallow: *index.php*
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: *bitrix*
Disallow: /*clear_cache=
Disallow: /*clear_cache_session=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*ORDER_BY
Disallow: /*print*
Disallow: /*action*
Disallow: /*register=
Disallow: /*password*
Disallow: /*login=
Disallow: /*type=
Disallow: /*sort=
Disallow: /*order=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*backurl=
Disallow: /*back_url=
Disallow: /*BACKURL=
Disallow: /*BACK_URL=
Disallow: /*back_url_admin=
Disallow: /*?utm_source=
Disallow: *?arrFilter*
Allow: */bitrix/*css
Allow: */bitrix/*js
Allow: */upload/*.jpg
Allow: */upload/*.JPG
Allow: */upload/*.jpeg
Allow: */upload/*.png
User-agent: Yandex
Disallow: /auth*
Disallow: /basket*
Disallow: /order*
Disallow: /personal/
Disallow: /search/
Disallow: /test/
Disallow: /ajax/
Disallow: *index.php*
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: *bitrix*
Disallow: /*clear_cache=
Disallow: /*clear_cache_session=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*ORDER_BY
Disallow: /*register=
Disallow: /*password*
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*backurl=
Disallow: /*back_url=
Disallow: /*BACKURL=
Disallow: /*BACK_URL=
Disallow: /*back_url_admin=
Disallow: *?arrFilter*
Allow: */bitrix/*css
Allow: */bitrix/*js
Allow: */upload/*.jpg
Allow: */upload/*.JPG
Allow: */upload/*.jpeg
Allow: */upload/*.png
Clean-param: sort&action&print&order&type&utm&utm_source&openstat&utm&from&gclid&yclid&ymclid&fbclid&tid&cm_id&utm_referrer&etext&block&source
Sitemap: https://example.com/sitemap.xml #указать действительный адресШаблон robots.txt для сайтов на WordPress :
User-agent: *
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: /tag/
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-param: utm&utm_source&utm_medium&utm_campaign&openstat&from&gclid&yclid&ymclid&fbclid&tid&cm_id&utm_referrer&etext
Sitemap: https://example.com/sitemap.xml #указать действительный адресШаблон robots.txt для сайтов на Bitrix
Шаблон robots.txt для сайтов на WordPress
Успешная индексация нового сайта зависит от многих слагаемых. Один из них — файл robots.txt, с правильным заполнением которого должен быть знаком любой начинающий веб-мастер. Обновили материал для новичков.
Подробно о правилах составления файла в полном руководстве «Как составить robots.txt самостоятельно».
А в этом материале основы для начинающих, которые хотят быть в курсе профессиональных терминов.
Что такое robots.txt
Файл robots.txt — это документ в формате .txt, содержащий инструкции по индексации конкретного сайта для поисковых ботов. Он указывает поисковикам, какие страницы веб-ресурса стоит проиндексировать, а какие не нужно допустить к индексации.
Поисковый робот, придя к вам на сайт, первым делом пытается отыскать robots.txt. Если робот не нашел файл или он составлен неправильно, бот будет изучать сайт по своему собственному усмотрению. Далеко не факт, что он начнет с тех страниц, которые нужно вводить в поиск в первую очередь (новые статьи, обзоры, фотоотчеты и так далее). Индексация нового сайта может затянуться. Поэтому веб-мастеру нужно вовремя позаботиться о создании правильного файла robots.txt.
На некоторых конструкторах сайтов файл формируется сам. Например, Wix автоматически создает robots.txt. Чтобы посмотреть файл, добавьте к домену «/robots.txt». Если вы увидите там странные элементы типа «noflashhtml» и «backhtml», не пугайтесь: они относятся к структуре сайтов на платформе и не влияют на отношение поисковых систем.
Зачем нужен robots.txt
Казалось бы, зачем запрещать индексировать какое-то содержимое сайта? Далеко не весь контент, из которого состоит сайт, нужен поисковым роботам. Есть системные файлы, есть дубликаты страниц, есть рубрики ключевых слов и много чего еще есть, что вовсе не обязательно индексировать. Есть одно но:
Содержимое файла robots.txt — это рекомендации для ботов, а не жесткие правила. Рекомендации боты могут проигнорировать.
Google предупреждает, что через robots.txt нельзя заблокировать страницы для показа в Google. Даже если вы закроете доступ к странице в robots.txt, если на какой-то другой странице будет ссылка на эту, она может попасть в индекс. Лучше использовать и ограничения в robots, и другие методы запрета:
Запрет индексирования сайта, Яндекс
Блокировка индексирования, Google
Тем не менее, без robots.txt больше вероятность, что информация, которая должна быть скрыта, попадет в выдачу, а это бывает чревато раскрытием персональных данных и другими проблемами.
Из чего состоит robots.txt
Файл должен называться только «robots.txt» строчными буквами и никак иначе. Его размещают в корневом каталоге — https://site.com/robots.txt в единственном экземпляре. В ответ на запрос он должен отдавать HTTP-код со статусом 200 ОК. Вес файла не должен превышать 32 КБ. Это максимум, который будет воспринимать Яндекс, для Google robots может весить до 500 КБ.
Внутри все должно быть на латинице, все русские названия нужно перевести с помощью любого Punycode-конвертера. Каждый префикс URL нужно писать на отдельной строке.
В robots.txt с помощью специальных терминов прописываются директивы (команды или инструкции). Кратко о директивах для поисковых ботах:
«Us-agent:» — основная директива robots.txt
Используется для конкретизации поискового робота, которому будут давать указания. Например, User-agent: Googlebot или User-agent: Yandex.
В файле robots.txt можно обратиться ко всем остальным поисковым системам сразу. Команда в этом случае будет выглядеть так: User-agent: *. Под специальным символом «*» принято понимать «любой текст».
После основной директивы «User-agent:» следуют конкретные команды.
Команда «Disallow:» — запрет индексации в robots.txt
При помощи этой команды поисковому роботу можно запретить индексировать веб-ресурс целиком или какую-то его часть. Все зависит от того, какое расширение у нее будет.
User-agent: Yandex Disallow: /
Такого рода запись в файле robots.txt означает, что поисковому роботу Яндекса вообще не позволено индексировать данный сайт, так как запрещающий знак «/» не сопровождается какими-то уточнениями.
User-agent: Yandex Disallow: /wp-admin
На этот раз уточнения имеются и касаются они системной папки wp-admin в CMS WordPress. То есть индексирующему роботу рекомендовано отказаться от индексации всей этой папки.
Команда «Allow:» — разрешение индексации в robots.txt
Антипод предыдущей директивы. При помощи тех же самых уточняющих элементов, но используя данную команду в файле robots.txt, можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу.
User-agent: * Allow: /catalog Disallow: /
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено.
На практике «Allow:» используется не так уж и часто. В ней нет надобности, поскольку она применяется автоматически. В robots «разрешено все, что не запрещено». Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации какое-то содержимое, а весь остальной контент ресурса воспринимается поисковым роботом как доступный для индексации.
Директива «Sitemap:» — указание на карту сайта
«Sitemap:
» указывает индексирующему роботу правильный путь к так Карте сайта — файлам sitemap.xml
и sitemap.xml.gz в случае с CMS WordPress.
User-agent: * Sitemap: http://pr-cy.ru/sitemap.xml Sitemap: http://pr-cy.ru/sitemap.xml.gz
Прописывание команды в файле robots.txt поможет поисковому роботу быстрее проиндексировать Карту сайта. Это ускорит процесс попадания страниц ресурса в выдачу.
Файл robots.txt готов — что дальше
Итак, вы создали текстовый документ robots.txt с учетом особенностей вашего сайта. Его можно сделать автоматически, к примеру, с помощью нашего инструмента.
Что делать дальше:
- проверить корректность созданного документа, например, посредством сервиса Яндекса;
- при помощи FTP-клиента закачать готовый файл в корневую папку своего сайта. В ситуации с WordPress речь обычно идет о системной папке Public_html.
Дальше остается только ждать, когда появятся поисковые роботы, изучат ваш robots.txt, а после возьмутся за индексацию вашего сайта.
Как посмотреть robots.txt чужого сайта
Если вам интересно сперва посмотреть на готовые примеры файла robots.txt в исполнении других, то нет ничего проще. Для этого в адресной строке браузера достаточно ввести site.ru/robots.txt. Вместо «site.ru» — название интересующего вас ресурса.