
Пройдите тест, узнайте какой профессии подходите
Работать самостоятельно и не зависеть от других
Работать в команде и рассчитывать на помощь коллег
Организовывать и контролировать процесс работы
Введение в MySQL
MySQL — это одна из самых популярных систем управления базами данных (СУБД) на основе языка SQL (Structured Query Language). Она используется для хранения, управления и извлечения данных в различных приложениях, от веб-сайтов до корпоративных систем. MySQL является открытым программным обеспечением и поддерживается множеством операционных систем, включая Windows, Linux и macOS. В этом руководстве мы рассмотрим основные аспекты работы с MySQL, начиная с установки и настройки и заканчивая выполнением базовых SQL-команд и управлением базами данных.
MySQL обладает высокой производительностью и масштабируемостью, что делает её идеальной для использования в проектах любого размера. Она поддерживает множество функций, таких как транзакции, репликация и кластеризация, что позволяет создавать надежные и отказоустойчивые системы. Кроме того, MySQL имеет обширное сообщество пользователей и разработчиков, что обеспечивает доступ к большому количеству ресурсов и документации.

Установка и настройка MySQL
Установка MySQL на Windows
- Скачивание установочного файла: Перейдите на официальный сайт MySQL и скачайте установочный файл для Windows. Важно убедиться, что вы скачиваете последнюю стабильную версию.
- Запуск установщика: Запустите скачанный файл и следуйте инструкциям мастера установки. Процесс установки довольно прост и интуитивно понятен.
- Выбор типа установки: Выберите тип установки (обычно рекомендуется «Developer Default»). Этот тип установки включает все необходимые компоненты для разработки и тестирования.
- Настройка учетной записи root: Установите пароль для учетной записи root, которая имеет полные права на управление базой данных. Убедитесь, что пароль надежный и запомните его.
- Настройка службы MySQL: Убедитесь, что служба MySQL настроена на автоматический запуск. Это позволит базе данных автоматически запускаться при загрузке системы.
Установка MySQL на Linux
- Обновление пакетов: Обновите список пакетов вашей системы командой
sudo apt update. Это обеспечит установку последних версий пакетов и зависимостей. - Установка MySQL: Установите MySQL командой
sudo apt install mysql-server. Эта команда установит сервер MySQL и все необходимые зависимости. - Запуск службы MySQL: Убедитесь, что служба MySQL запущена командой
sudo systemctl start mysql. Вы также можете настроить автоматический запуск службы при загрузке системы. - Настройка безопасности: Запустите скрипт безопасности MySQL командой
sudo mysql_secure_installationи следуйте инструкциям. Этот скрипт поможет вам настроить основные параметры безопасности, такие как удаление анонимных пользователей и тестовой базы данных.
Основные команды SQL
SELECT
Команда SELECT используется для извлечения данных из базы данных. Пример:
Эта команда извлекает все записи из таблицы users. Вы также можете указать конкретные столбцы, которые хотите извлечь:
INSERT
Команда INSERT используется для добавления новых записей в таблицу. Пример:
Эта команда добавляет новую запись в таблицу users с именем John Doe и электронной почтой john@example.com.
UPDATE
Команда UPDATE используется для изменения существующих записей. Пример:
Эта команда обновляет электронную почту пользователя с именем John Doe на john.doe@example.com.
DELETE
Команда DELETE используется для удаления записей из таблицы. Пример:
Эта команда удаляет запись пользователя с именем John Doe из таблицы users.
Создание и управление базами данных
Создание базы данных
Для создания новой базы данных используется команда CREATE DATABASE. Пример:
Эта команда создает новую базу данных с именем mydatabase. После создания базы данных вы можете начать создавать таблицы и добавлять данные.
Создание таблицы
Для создания таблицы используется команда CREATE TABLE. Пример:
Эта команда создает таблицу users с тремя столбцами: id, name и email. Столбец id является первичным ключом и автоматически увеличивается при добавлении новых записей.
Управление таблицами
- Добавление столбца:
ALTER TABLE users ADD age INT; - Удаление столбца:
ALTER TABLE users DROP COLUMN age; - Изменение типа данных столбца:
ALTER TABLE users MODIFY COLUMN name TEXT;
Эти команды позволяют вам изменять структуру таблицы после её создания. Например, вы можете добавить новый столбец age, удалить существующий столбец age или изменить тип данных столбца name.
Практические примеры и советы
Пример создания базы данных и таблицы
- Создание базы данных:
- Выбор базы данных:
- Создание таблицы студентов:
Этот пример демонстрирует процесс создания базы данных school, выбора этой базы данных и создания таблицы students с четырьмя столбцами: id, name, age и grade.
Советы по оптимизации запросов
- Используйте индексы: Индексы ускоряют поиск данных. Пример создания индекса:
- Избегайте SELECT *: Указывайте конкретные столбцы, чтобы уменьшить объем передаваемых данных. Например, вместо
SELECT *используйтеSELECT name, age. - Кэшируйте результаты: Используйте кэширование для часто выполняемых запросов. Это может значительно уменьшить нагрузку на базу данных и ускорить выполнение запросов.
Работа с внешними ключами
Внешние ключи помогают поддерживать целостность данных. Пример создания таблицы с внешним ключом:
Этот пример демонстрирует создание двух таблиц: classes и enrollments. Таблица enrollments содержит внешние ключи, которые ссылаются на таблицы students и classes, что помогает поддерживать целостность данных.
Резервное копирование и восстановление базы данных
- Резервное копирование: Используйте команду
mysqldumpдля создания резервной копии базы данных. Пример:
- Восстановление: Для восстановления базы данных используйте команду
mysql. Пример:
Резервное копирование и восстановление базы данных являются важными задачами для обеспечения безопасности данных. Регулярное создание резервных копий поможет вам избежать потери данных в случае сбоя системы или других непредвиденных обстоятельств.
Полезные инструменты
- phpMyAdmin: Веб-интерфейс для управления MySQL. Этот инструмент позволяет выполнять различные операции с базой данных через веб-браузер, что делает его удобным для пользователей, не знакомых с командной строкой.
- MySQL Workbench: Графический инструмент для проектирования и администрирования баз данных. MySQL Workbench предоставляет мощные средства для моделирования данных, разработки SQL-запросов и администрирования серверов MySQL.
Эти советы и примеры помогут вам начать работу с MySQL и эффективно управлять базами данных. Удачи в изучении! 🚀
Читайте также

Проверьте, как это работает!
Базы данных и веб-приложения могут принести большую пользу вашему бизнесу. Проектирование базы данных играет важнейшую роль в достижении ваших целей независимо от того, что вам нужно: управлять сведениями о сотрудниках, предоставлять еженедельные отчеты по данным или отслеживать заказы клиентов. Уделив время изучению всех нюансов проектирования баз данных, вы сможете создавать базы, которые будут не только отвечать вашим текущим требованиям, но и адаптироваться к изменениям.
Важно: Веб-приложения Access отличаются от классических баз данных. В этой статье не рассматривается проектирование веб-приложений.
Понятия и термины
Для начала рассмотрим основные термины и понятия. Чтобы спроектировать полезную базу данных, необходимо создать таблицы с данными по одному объекту. В таблицах можно собрать все данные по этому объекту и отобразить их полях, которые содержат наименьшую единицу данных.
|
Реляционные базы данных |
База данных, в которой данные разделены на таблицы по типу электронных. Каждая таблица включает данные по одному объекту, например по клиентам (одна таблица) или товарам (другая таблица). |
|
Записи и поля |
Области хранения отдельных данных в таблице. В каждой строке (или записи) хранится уникальный элемент данных, например имя клиента. Столбцы (или поля) содержат сведения по каждой точке данных в виде наименьшей единицы: имя может находиться в одном столбце, а фамилия — в другом. |
|
Первичный ключ |
Значение, которое обеспечивает уникальность каждой записи. Допустим, есть два клиента с одинаковыми именами, например Юрий Богданов. Но у одного из них первичный ключ записей — 12, а у другого — 58. |
|
Иерархические отношения |
Общие связи между таблицами. Например, один клиент может иметь несколько заказов. Родительские таблицы имеют первичные ключи. Дочерние таблицы имеют внешние ключи, которые являются значениями из первичного ключа, которые показывают, как записи дочерней таблицы связаны с родительской таблицей. Эти ключи связаны связью. |
Что понимать под хорошим проектированием базы данных?
В основе проектирования хорошей базы данных лежат два принципа:
-
Избегайте повторяющихся сведений (избыточных данных). Они занимают много места на диске и повышают вероятность ошибок.
-
Следите за правильностью и полнотой данных. Неполные или неправильные сведения отображаются в запросах и отчетах, что в конечном итоге может привести к принятию ошибочных решений.
Чтобы избежать этих проблем:
-
Разделяйте информацию в базе данных по таблицам для отдельных объектов. Избегайте повторения информации в нескольких таблицах. (Например, имена клиентов должны находиться только в одной таблице.)
-
Объединяйте таблицы с помощью ключей, а не путем дублирования данных.
-
Используйте процессы, которые обеспечивают точность и целостность информации в базе данных.
-
Проектируйте базу данных с учетом своих требований к обработке данных и созданию отчетов по ним.
Чтобы повысить пользу баз данных в долгосрочной перспективе, выполните следующие пять шагов по проектированию:
Шаг 1. Определение назначения базы данных
Прежде чем начать, сформулируйте цель базы данных.
Чтобы спроектировать специализированную базу данных, определите ее назначение и часто обращайтесь к этому определению. Если вам нужна небольшая база данных для домашнего бизнеса, можно дать простое определение, например: «Эта база данных содержит список сведений о клиентах для рассылки и создания отчетов». Для корпоративной базы данных можно дать определение из нескольких абзацев, в котором будет описано, когда и как люди с различными ролями используют базу данных и содержащуюся в ней информацию. Создайте специальное и подробное определение цели и периодически обращайтесь к нему в процессе проектирования.
Шаг 2. Поиск и упорядочение необходимых сведений
Соберите все типы данных, которые необходимо записывать, например названия товаров и номера заказов.
Начните с существующих сведений и методов отслеживания. Предположим, вы записываете заказы на покупку в книге учета или ведете записи о клиентах в бумажных формах. Используйте эти источники, чтобы создать список собираемых сведений (например, всех полей в формах). Если в настоящее время вы не собираете важные сведения, подумайте, какие дискретные данные вам необходимы. Каждый отдельный тип данных становится полем в вашей базе данных.
Не беспокойтесь, если ваш первый список несовершенен — вы сможете доработать его со временем. Однако всегда помните о людях, которые будут пользоваться этой информацией, и учитывайте их мнение.
Затем подумайте, что вы ждете от своей базы данных и какие отчеты или рассылки вы хотите создавать. Убедитесь, что вы собираете данные, которые отвечают этим целям. Например, если вам нужен отчет о продажах по регионам, вам необходимо собирать данные о продажах на региональном уровне. Попробуйте сделать набросок желаемого отчета, используя фактические данные. Затем составьте список данных, необходимых для создания отчета. Сделайте то же самое для рассылок или других выходных данных, которые нужно получить из базы данных.
Пример
Предположим, вы даете клиентам возможность подписаться на периодическую рассылку (или отказаться от нее) и хотите распечатать список подписавшихся пользователей. Вам нужно создать столбец «Отправка почты» в таблице «Клиенты» с допустимыми значениями «Да» и «Нет».
Для тех, кто хочет получать рассылку, вам нужно добавить электронный адрес, что также требует отдельного поля. Если вы хотите использовать соответствующее обращение к получателю (например, «Уважаемый» или «Уважаемая»), добавьте поле «Обращение». Если в письмах вы хотите обращаться к клиентам по имени, добавьте поле «Имя».
Совет: Не забывайте разбивать данные на наименьшие единицы, например имя и фамилию в таблице «Клиенты». Вообще, если вы хотите выполнять сортировку, поиск, вычисления или отчет на основе элемента данных (например, фамилии клиента), следует поместить этот элемент в отдельное поле.
Шаг 3. Разделение данных по таблицам
Разделите элементы данных на основные объекты, например товары, клиенты или заказы. Каждый объект выносится в таблицу.
После создания списка необходимых сведений определите основные объекты, необходимые для организации данных. Избегайте повторения данных между объектами. Например, предварительный список для базы данных по продажам товаров может выглядеть так:
К основным объектам относятся клиенты, поставщики, товары и заказы. Поэтому начните с соответствующих четырех таблиц: по клиентам, поставщикам и т. д. Возможно, ваша конечная цель состоит не в этом, но это будет хорошим началом.
Примечание: Лучшие базы данных содержат несколько таблиц. Избегайте искушения поместить все данные в одну таблицу. Это приведет к повторению информации, увеличению размера базы данных и повышению вероятности ошибок. Каждый элемент данных должен записываться только один раз. Если вы обнаружите повторяющиеся сведения, например адрес поставщика, измените структуру базы данных так, чтобы эта информация находилась в отдельной таблице.
Чтобы понять, почему чем больше таблиц, тем лучше, рассмотрим следующую таблицу:
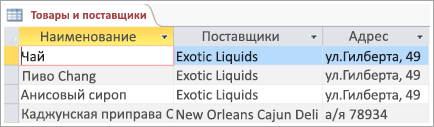
Каждая строка содержит сведения как о продукте, так и о его поставщике. Так как у вас может быть много продуктов от одного поставщика, имя поставщика и сведения об адресе должны повторяться много раз. Это пустая трата места на диске. Вместо этого запишите сведения о поставщике только один раз в отдельной таблице Поставщики, а затем свяжите ее с таблицей Products.
Вторая проблема проектирования возникает тогда, когда нужно изменить сведения о поставщике. Предположим, вам нужно изменить адрес поставщика. А так как адрес указан во многих полях, можно случайно изменить его в одном поле и забыть изменить в других. Эту проблему можно решить, записав адрес поставщика только в одном поле.
Наконец, предположим, у вас есть только один товар, поставляемый компанией Coho Winery, и вы хотите удалить этот товар, но сохранить имя и адрес поставщика. Как удалить запись о товаре, не потеряв сведений о поставщике, с такой структурой базы данных? Это невозможно. Так как каждая запись содержит информацию о товаре вместе с данными о поставщике, их невозможно удалить по отдельности. Чтобы разделить эти сведения, необходимо сделать из одной таблицы две: одну — для сведений о товаре, другую —для сведений о поставщике. И только после этого удаление записи о товаре не будет приводить к удалению сведений о поставщике.
Шаг 4. Превращение элементов данных в столбцы
Определите, какие данные необходимо хранить в каждой таблице. Эти отдельные элементы данных становятся полями в таблице. Например, таблица «Сотрудники» может содержать такие поля, как «Фамилия», «Имя» и «Дата приема на работу».
После выбора объекта для таблицы базы данных столбцы в ней должны содержать сведения только об этом объекте. Например, таблица по товарам должна содержать сведения только о товарах, а не о поставщиках.
Чтобы определить, какие данные нужно отследить в таблице, используйте ранее созданный список. Например, таблица «Клиенты» может содержать такие поля: «Имя», «Фамилия», «Адрес», «Отправка почты», «Обращение» и «Электронный адрес.» Каждая запись (клиент) в таблице содержит один и тот же набор столбцов, поэтому по каждому клиенту можно хранить одинаковую информацию.
Создайте свой первый список, а затем просмотрите и уточните его. Не забудьте разбить информацию на наименьшие возможные поля. Например, если в исходном списке в качестве поля «Адрес», разбейте его на «Адрес улицы», «Город», «Штат» и «Почтовый индекс» или , если ваши клиенты являются глобальными, на еще большее число полей. Таким образом, например, вы можете выполнять рассылки в правильном формате или сообщать о заказах по состоянию.
Доработав столбцы с данными во всех таблицах, вы готовы выбрать первичный ключ для каждой из них.
Шаг 5. Задание первичных ключей
Выберите первичный ключ для каждой таблицы. Первичный ключ, например код товара или код заказа, является уникальным идентификатором каждой записи. Если у вас нет явного уникального идентификатора, его можно создать с помощью Access.
Вам нужно однозначно определить каждую строку в каждой таблице. Вернемся к примеру с двумя клиентами с одинаковым именем. Так как у них одно и то же имя, им нужно дать уникальный идентификатор.
Поэтому каждая таблица должна содержать столбец (или набор столбцов), который однозначно определяет каждую строку. Это и есть первичный ключ. Он часто является уникальным числом, например кодом сотрудника или порядковым номером Используя первичные ключи, Access быстро связывает данные из нескольких таблиц и сводит их для вас воедино.
Иногда первичный ключ состоит из нескольких полей. Например, в таблице «Сведения о заказе», которая содержит позиции по заказам, первичный ключ может включать два столбца: «Код заказа» и «Код товара». Если в первичном ключе используется несколько столбцов, он также называется составным ключом.
Если у вас уже есть уникальный идентификатор для данных в таблице, например номера товаров, однозначно определяющие каждый продукт в каталоге, используйте его, но только если эти значения соответствуют следующим правилам первичных ключей:
-
Идентификатор для каждой записи всегда уникален. Повторяющиеся значения в первичном ключе не допускаются.
-
Для каждого элемента всегда существует значение. Каждая запись в таблице должна иметь первичный ключ. Если вы создаете ключ с помощью нескольких столбцов, например «Группа позиций» и «Код позиции», всегда должны присутствовать оба значения.
-
Первичный ключ представляет собой неизменное значение. Так как на ключи ссылаются другие таблицы, при любом изменении первичного ключа в одной таблице необходимо изменить его во всех других. Частые изменения повышают риск возникновения ошибок.
Если у вас нет явного идентификатора, то в качестве первичного ключа используйте произвольный уникальный номер. Например, вы можете присвоить каждому заказу уникальный номер, только чтобы идентифицировать его.
Совет: Чтобы создать уникальный номер в качестве первичного ключа, добавьте столбец, используя тип данных «Счетчик». Этот тип данных автоматически присваивает каждой записи уникальное числовое значение. Такой идентификатор не содержит фактических сведений о строке, которую он представляет. Он идеален в качестве первичного ключа, так как в отличие от ключей, содержащих фактические данные о строке (например, номер телефона или имя клиента), числа не изменяются.
Вам нужны дополнительные возможности?
Руководство по именованию полей, элементов управления и объектов
Общие сведения о таблицах
Обучение работе с Excel
Обучение работе с Outlook

📝 PostgreSQL — это мощная, открытая система управления реляционными базами данных (СУРБД), известная своей надежностью, масштабируемостью и соблюдением стандартов SQL.
Она широко используется как в крупных корпорациях, так и у малых предприятий и разработчиков благодаря своей гибкости и богатым функциональным возможностям.
🖥️ Установка PostgreSQL
Перед началом работы убедитесь, что на вашем компьютере установлен PostgreSQL.
Установить его можно с официального сайта postgresql.org.

Выберите версию для вашей операционной системы (Windows, macOS, Linux) и следуйте инструкциям установщика.
🖥️ Настройка базы данных
После установки PostgreSQL по умолчанию создается одна база данных с именем postgres
Для управления базами данных используется утилита pgAdmin, которая также устанавливается вместе с PostgreSQL.

-
Запустите
pgAdminиз меню вашей операционной системы. -
В левой панели найдите сервер (обычно называется
localhostили имя вашего компьютера), щелкните по нему правой кнопкой мыши и выберите «Create» ➡️ «Database» -
Введите имя для вашей новой базы данных, например,
mydatabaseи нажмите «Save»
🖥️ Создание таблиц
Теперь, когда у вас есть база данных, можно начать создавать таблицы.
Откройте вашу базу данных в pgAdmin, щелкните правой кнопкой мыши на папке «Tables» и выберите «Create» ➡️ «Table».
В открывшемся диалоговом окне введите следующий SQL-скрипт для создания простой таблицы пользователей:
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
email VARCHAR(255) UNIQUE NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);Этот скрипт создает таблицу с четырьмя столбцами: id, name, email и created_at
Столбец id автоматически генерирует уникальный идентификатор для каждой записи.
🖥️ Вставка данных
Чтобы добавить данные в таблицу, используйте оператор INSERT INTO
Например:
INSERT INTO users (name, email)
VALUES ('Иван Иванов', 'ivan@example.com');🖥️ Запросы к данным
Для извлечения данных используйте оператор SELECT
Например, чтобы получить всех пользователей, введите:
SELECT * FROM users;🖥️ Обновление и удаление данных
Для обновления данных в таблице используйте оператор UPDATE
Например, чтобы изменить email пользователя с id=1, используйте следующий запрос:
UPDATE users
SET email = 'newemail@example.com'
WHERE id = 1;Для удаления данных используйте оператор DELETE
Например, чтобы удалить пользователя с id=1, используйте:
DELETE FROM users WHERE id = 1;▶️ Заключение
Это базовое руководство по началу работы с PostgreSQL.
Эта СУРБД предлагает множество других возможностей, таких как транзакции, индексы, наследование таблиц и многое другое.
DISCLAIMER: 5 интересных фактов о PostgreSQL
-
Постоянное развитие с 1986 года: PostgreSQL имеет долгую историю, начиная с проекта Ingres в 1970-х годах. Он был переписан с нуля в начале 1980-х годов и с тех пор постоянно развивается и совершенствуется.
-
Строгая поддержка стандартов SQL: PostgreSQL известен своей строгой поддержкой стандартов SQL. Он регулярно обновляется с новыми функциями, которые соответствуют последним версиям стандарта SQL, и предлагает множество расширений, которые позволяют пользователям настраивать и расширять функциональность базы данных.
-
Технология версионирования с откатом (WAL): PostgreSQL использует технологию версионирования с откатом (Write Ahead Logging), которая обеспечивает высокую надежность и целостность данных. Эта технология гарантирует, что все изменения в базе данных будут зафиксированы в журнале перед их применением, что позволяет быстро восстановить базу данных в случае сбоя или ошибки.
-
Расширяемость и модульность: PostgreSQL предлагает высокую степень расширяемости и модульности. Пользователи могут создавать собственные типы данных, функции, операторы и индексы, что делает его идеальным выбором для сложных и специализированных приложений. Кроме того, существует большое количество сторонних расширений, которые расширяют функциональность PostgreSQL в области машинного обучения, геопространственных данных и многого другого.
-
Широкое сообщество и поддержка: PostgreSQL имеет огромное сообщество разработчиков и пользователей по всему миру, которые активно вносят свой вклад в развитие и поддержку базы данных. Это сообщество также предлагает обширные ресурсы, включая документацию, форумы и обучающие материалы, что делает PostgreSQL одной из самых поддерживаемых и документированных систем управления базами данных.
Установка
Когда вы изучаете новый язык, самым важным аспектом является практика. Одно дело – прочитать статью и совсем другое – применить полученную информацию. Давайте начнем с установки базы данных на компьютер.
Первый шаг – установить SQL
Мы будем использовать PostgreSQL (Postgres) – достаточно распространенный SQL диалект. Для этого откроем страницу загрузки, выберем операционную систему (в моем случае Windows), и запустим установку. Если вы установите пароль для вашей базы данных, постарайтесь сразу не забыть его, он нам дальше понадобится. Поскольку наша база будет локальной, можете использовать простой пароль, например: admin.
Следующий шаг – установка pgAdmin
pgAdmin – это графический интерфейс пользователя (GUI – graphical user interface), который упрощает взаимодействие с базой данных PostgreSQL. Перейдите на страницу загрузки, выберите вашу операционную систему и следуйте указаниям (в статье используется Postgres 14 и pgAdmin 4 v6.3.).
После установки обоих компонентов открываем pgAdmin и нажимаем Add new server. На этом шаге установится соединение с существующим сервером, именно поэтому необходимо сначала установить Postgres. Я назвал свой сервер home и использовал пароль, указанный при установке.
Теперь всё готово к созданию таблиц. Давайте создадим набор таблиц, которые моделируют школу. Нам необходимы таблицы: ученики, классы, оценки. При создании модели данных необходимо учитывать, что в одном классе может быть много учеников, а у ученика может быть много оценок (такое отношение называется «один ко многим»).
Мы можем создать таблицы напрямую в pgAdmin, но вместо этого мы напишем код, который можно будет использовать в дальнейшем, например, для пересоздания таблиц. Для создания запроса, который создаст наши таблицы, нажимаем правой кнопкой мыши на postgres (пункт расположен в меню слева home → Databases (1) → postgres и далее выбираем Query Tool.
Начнем с создания таблицы классов (classrooms). Таблица будет простой: она будет содержать идентификатор id и имя учителя – teacher. Напишите следующий код в окне запроса (query tool) и запустите (run или F5).
DROP TABLE IF EXISTS classrooms CASCADE;
CREATE TABLE classrooms (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
teacher VARCHAR(100)
);
В первой строке фрагмент DROP TABLE IF EXISTS classrooms удалит таблицу classrooms, если она уже существует. Важно учитывать, что Postgres, не позволит нам удалить таблицу, если она имеет связи с другими таблицами, поэтому, чтобы обойти это ограничение (constraint) в конце строки добавлен оператор CASCADE. CASCADE – автоматически удалит или изменит строки из зависимой таблицы, при внесении изменений в главную. В нашем случае нет ничего страшного в удалении таблицы, поскольку, если мы на это пошли, значит мы будем пересоздавать всё с нуля, и остальные таблицы тоже удалятся.
Добавление DROP TABLE IF EXISTS перед CREATE TABLE позволит нам систематизировать схему нашей базы данных и создать скрипты, которые будут очень удобны, если мы захотим внести изменения – например, добавить таблицу, изменить тип данных поля и т. д. Для этого нам просто нужно будет внести изменения в уже готовый скрипт и перезапустить его.
Ничего нам не мешает добавить наш код в систему контроля версий. Весь код для создания базы данных из этой статьи вы можете посмотреть по ссылке.
Также вы могли обратить внимание на четвертую строчку. Здесь мы определили, что колонка id является первичным ключом (primary key), что означает следующее: в каждой записи в таблице это поле должно быть заполнено и каждое значение должно быть уникальным. Чтобы не пришлось постоянно держать в голове, какое значение id уже было использовано, а какое – нет, мы написали GENERATED ALWAYS AS IDENTITY, этот приём является альтернативой синтаксису последовательности (CREATE SEQUENCE). В результате при добавлении записей в эту таблицу нам нужно будет просто добавить имя учителя.
И в пятой строке мы определили, что поле teacher имеет тип данных VARCHAR (строка) с максимальной длиной 100 символов. Если в будущем нам понадобится добавить в таблицу учителя с более длинным именем, нам придется либо использовать инициалы, либо изменять таблицу (alter table).
Теперь давайте создадим таблицу учеников (students). Новая таблица будет содержать: уникальный идентификатор (id), имя ученика (name), и внешний ключ (foreign key), который будет указывать (references) на таблицу классов.
DROP TABLE IF EXISTS students CASCADE;
CREATE TABLE students (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
name VARCHAR(100),
classroom_id INT,
CONSTRAINT fk_classrooms
FOREIGN KEY(classroom_id)
REFERENCES classrooms(id)
);
И снова мы перед созданием новой таблицы удаляем старую, если она существует, добавляем поле id, которое автоматически увеличивает своё значение и имя с типом данных VARCHAR (строка) и максимальной длиной 100 символов. Также в эту таблицу мы добавили колонку с идентификатором класса (classroom_id), и с седьмой по девятую строку установили, что ее значение указывает на колонку id в таблице классов (classrooms).
Мы определили, что classroom_id является внешним ключом. Это означает, что мы задали правила, по которым данные будут записываться в таблицу учеников (students). То есть Postgres на данном этапе не позволит нам вставить строку с данными в таблицу учеников (students), в которой указан идентификатор класса (classroom_id), не существующий в таблице classrooms. Например: у нас в таблице классов 10 записей (id с 1 до 10), система не даст нам вставить данные в таблицу учеников, у которых указан идентификатор класса 11 и больше.
INSERT INTO students
(name, classroom_id)
VALUES
('Matt', 1);
/*
ERROR: insert or update on table "students" violates foreign
key constraint "fk_classrooms"
DETAIL: Key (classroom_id)=(1) is not present in table
"classrooms".
SQL state: 23503
*/
Теперь давайте добавим немного данных в таблицу классов (classrooms). Так как мы определили, что значение в поле id будет увеличиваться автоматически, нам нужно только добавить имена учителей.
INSERT INTO classrooms
(teacher)
VALUES
('Mary'),
('Jonah');
SELECT * FROM classrooms;
/*
id | teacher
-- | -------
1 | Mary
2 | Jonah
*/
Прекрасно! Теперь у нас есть записи в таблице классов, и мы можем добавить данные в таблицу учеников, а также установить нужные связи (с таблицей классов).
INSERT INTO students
(name, classroom_id)
VALUES
('Adam', 1),
('Betty', 1),
('Caroline', 2);
SELECT * FROM students;
/*
id | name | classroom_id
-- | -------- | ------------
1 | Adam | 1
2 | Betty | 1
3 | Caroline | 2
*/
Но что же случится, если у нас появится новый ученик, которому ещё не назначили класс? Неужели нам придется ждать, пока станет известно в каком он классе, и только после этого добавить его запись в базу данных?
Конечно же, нет. Мы установили внешний ключ, и он будет блокировать запись, поскольку ссылка на несуществующий id класса невозможна, но мы можем в качестве идентификатора класса (classroom_id) передать null. Это можно сделать двумя способами: указанием null при записи значений, либо просто передачей только имени.
-- явно определим значение NULL
INSERT INTO students
(name, classroom_id)
VALUES
('Dina', NULL);
-- неявно определим значение NULL
INSERT INTO students
(name)
VALUES
('Evan');
SELECT * FROM students;
/*
id | name | classroom_id
-- | -------- | ------------
1 | Adam | 1
2 | Betty | 1
3 | Caroline | 2
4 | Dina | [null]
5 | Evan | [null]
*/
И наконец, давайте заполним таблицу успеваемости. Этот параметр, как правило, формируется из нескольких составляющих – домашние задания, участие в проектах, посещаемость и экзамены. Мы будем использовать две таблицы. Таблица заданий (assignments), как понятно из названия, будет содержать данные о самих заданиях, и таблица оценок (grades), в которой мы будем хранить данные о том, как ученик выполнил эти задания.
DROP TABLE IF EXISTS assignments CASCADE;
DROP TABLE IF EXISTS grades CASCADE;
CREATE TABLE assignments (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
category VARCHAR(20),
name VARCHAR(200),
due_date DATE,
weight FLOAT
);
CREATE TABLE grades (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
assignment_id INT,
score INT,
student_id INT,
CONSTRAINT fk_assignments
FOREIGN KEY(assignment_id)
REFERENCES assignments(id),
CONSTRAINT fk_students
FOREIGN KEY(student_id)
REFERENCES students(id)
);
Вместо того чтобы вставлять данные вручную, давайте загрузим их с помощью CSV-файла. Вы можете скачать файл из этого репозитория или создать его самостоятельно. Имейте в виду, чтобы разрешить pgAdmin доступ к данным, вам может понадобиться расширить права доступа к папке (в моем случае – это папка db_data).
COPY assignments(category, name, due_date, weight)
FROM 'C:/Users/mgsosna/Desktop/db_data/assignments.csv'
DELIMITER ','
CSV HEADER;
/*
COPY 5
Query returned successfully in 118 msec.
*/
COPY grades(assignment_id, score, student_id)
FROM 'C:/Users/mgsosna/Desktop/db_data/grades.csv'
DELIMITER ','
CSV HEADER;
/*
COPY 25
Query returned successfully in 64 msec.
*/
Теперь давайте проверим, что мы всё сделали верно. Напишем запрос, который покажет среднюю оценку, по каждому виду заданий с группировкой по учителям.
SELECT
c.teacher,
a.category,
ROUND(AVG(g.score), 1) AS avg_score
FROM
students AS s
INNER JOIN classrooms AS c
ON c.id = s.classroom_id
INNER JOIN grades AS g
ON s.id = g.student_id
INNER JOIN assignments AS a
ON a.id = g.assignment_id
GROUP BY
1,
2
ORDER BY
3 DESC;
/*
teacher | category | avg_score
------- | --------- | ---------
Jonah | project | 100.0
Jonah | homework | 94.0
Jonah | exam | 92.5
Mary | homework | 78.3
Mary | exam | 76.0
Mary | project | 69.5
*/
Отлично! Мы установили, настроили и наполнили базу данных.
***
Итак, в этой статье мы научились:
- создавать базу данных;
- создавать таблицы;
- наполнять таблицы данными;
- устанавливать связи между таблицами;
Теперь у нас всё готово, чтобы пробовать более сложные возможности SQL. Мы начнем с возможностей синтаксиса, которые, вероятно, вам еще не знакомы и которые откроют перед вами новые границы в написании SQL-запросов. Также мы разберем некоторый виды соединений таблиц (JOIN) и способы организации запросов в тех случаях, когда они занимают десятки или даже сотни строк.
В следующей части мы разберем:
- виды фильтраций в запросах;
- запросы с условиями типа if-else;
- новые виды соединений таблиц;
- функции для работы с массивами;
Материалы по теме
- 🐘 8 лучших GUI клиентов PostgreSQL в 2021 году
- 🐍🐬 Python и MySQL: практическое введение
- 🐍🗄️ Управление данными с помощью Python, SQLite и SQLAlchemy
В статье рассказывается:
В статье рассказывается:
- Особенности языка SQL
- Понятие реляционной СУБД
- Популярные сервисы для работы с SQL
- Основные команды SQL
-
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Работу с базами данных SQL, как структурированный язык запросов, выполняет практически идеально. Более того, он считается основным инструментом для взаимодействия с реляционными БД, позволяющим проводить с ними самые разные манипуляции.
И пусть возраст SQL насчитывает уже несколько десятилетий, он до сих пор используется весьма широко. Создать без него нечто серьезное весьма затруднительно.
SQL является непроцедурным языком программирования, предназначенным в первую очередь для описания данных, их выборки из реляционных БД и последующей обработки. Таким образом, SQL оперирует исключительно базами данных, и использовать только его для создания полноценного приложения нельзя.
В этом случае потребуются инструменты других языков, поддерживающих встраивание SQL-команд. Именно по причине своей специфичности SQL считают вспомогательным средством, позволяющим обрабатывать данные. Этот язык на практике используется только совместно с другими языками.

В общем случае прикладные средства программирования подразумевают создание процедур. SQL такими возможностями не обладает. Здесь нельзя указать способы решения задач — задается лишь смысл каждой конкретной задачи. Иначе говоря, в работе с базами данных SQL важны результаты, а не процедуры, приводящие к этим результатам.
Этот специфический язык программирования обладает одним важным свойством — возможностью доступа к реляционным базам данных. Иногда все реляционные БД ошибочно приравниваются к СУБД с применением средств SQL. На самом деле эти понятия следует различать.
Понятие реляционной СУБД
Не углубляясь в детали, можно дать такое определение: реляционной называется СУБД, использующая реляционную модель управления.
Доктор Е. Ф. Кодд в 1970 году опубликовал свою работу, где впервые было дано понятие реляционной модели. В публикации описывался некий математический аппарат, структурирующий данные и оперирующий ими. Основная идея состояла в представлении любых данных в виде абстрактной модели.
В соответствии с предложенной концепцией отношение между объектами (relation) представляет собой некую таблицу с данными. При этом существуют атрибуты (или признаки) отношения, которые соответствуют столбцам рассматриваемой таблицы. Сами данные предстают в виде наборов этих признаков и формируют записи (кортежи). Последние в свою очередь соответствуют табличным строкам.
Значения атрибутов каждого кортежа входят в домены, представляющие собой определенные наборы данных и задающие пределы допустимых значений.
Разберем это на примере. Существует домен «Неделя», в котором содержатся значения всех дней недели («Понедельник», «Вторник», …, «Воскресенье»). Атрибут, имеющий эти значения, называется «ДеньНедели». Тогда соответствие этого атрибута домену автоматически означает, что в одноименном столбце должны содержаться только перечисленные значения. Любые другие символы и группы символов недопустимы.
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ бесплатных нейросетей для упрощения работы и увеличения заработка
Только проверенные нейросети с доступом из России и свободным использованием
ТОП-100 площадок для поиска работы от GeekBrains
Список проверенных ресурсов реальных вакансий с доходом от 210 000 ₽
Уже скачали 34040
Также запрещается ввод сразу нескольких значений. Кроме того, требуется соблюдение условия атомарности. Иначе говоря, значения нельзя объединять друг с другом и разбивать их на более мелкие составляющие, сохранив при этом смысл. В случае присутствия в ячейке атрибута сразу двух значений и более (например, «Вторник» и «Среда») атомарность теряется. Тут можно выделить две части, сохранив смысл, но при дальнейшем разбитии слов на отдельные символы исходный смысл также утратится.
Другое важное свойство отношений в СУБД — замкнутость операций. Оно заключается в том, что любая операция над отношением порождает новое отношение. Благодаря этому свойству программисты SQL получают предсказуемые результаты математических действий. Также становится возможным представление операций в виде абстрактных выражений, обладающих разными уровнями вложенности.
Популярные сервисы для работы с SQL
Как язык работы с базами данных, SQL предполагает обязательное наличие установленной БД с доступом для подключения и выполнения запросов.
- LiveSQL
С помощью данного сервиса все SQL-операции можно выполнять в облаке. Это достаточно серьезное преимущество, ведь программистам здесь нет необходимости устанавливать и настраивать СУБД на локальную машину. Достаточно лишь зарегистрироваться.
Читайте также!
База данных MySQL: причины ее популярности

В целом процесс работы весьма простой. После регистрации необходимо войти под созданной учетной записью и выбрать пункт «SQL WorkSheet» в боковом меню слева. Откроется рабочее окно, куда, собственно, и нужно вводить SQL-запросы. Для выполнения запросов следует нажать кнопку «Run» над полем ввода текста.
- SQL Fiddle
Это еще одна популярная программа для работы с SQL базами данных, работающая как сервис и поддерживающая множество форматов БД. Регистрация здесь не требуется.
При входе на SQL Fiddle в первую очередь нужно выбрать подходящую для работы БД (например, Oracle). Далее создается схема из таблиц путем ввода текста специального ddl-скрипта. После нажатия на кнопку «Build Schema» можно приступать к выполнению SQL-запросов. Для их ввода используется панель «Query Panel», расположенная справа. Выполнение запроса осуществляется нажатием на «Run Sql». Результаты работы будут видны под рабочими панелями.
Основные команды SQL
Помимо трех основных команд (CREATE, UPDATE и DELETE), используются и несколько других. Перечислим их ниже с примерами для MySQL (поэтому везде после операторов стоит точка с запятой).
Итак, прежде всего создаем базу данных с текстовым наполнением.

Далее необходимо скачать файлы DLL.sql и InsertStatements.sql, а затем установить на компьютер СУБД MySQL. После чего в командной строке нужно ввести mysql -u root -p для входа в консоль MySQL.
Скачать
файл
Вводим пароль и в консоли выполняем ряд команд для создания БД с названием «study»:
CREATE DATABASE study;
USE study;
SOURCE <path_of_DLL.sql_file>;
SOURCE <path_of_InsertStatements.sql_file>;
Здесь перечислим основные команды, которые пригодятся нам в работе.
- SHOW DATABASES — просмотр доступных БД
- CREATE DATABASE — создание новой БД
- USE <database_name> — выбор БД для дальнейшей работы
- SOURCE <file.sql> — выполнение одной или нескольких команд, содержащихся в указанном файле.
- DROP DATABASE — удаление всей БД
- SHOW TABLES — вывод всех доступных таблиц в активной БД
- CREATE TABLE — создание новой таблицы в активной БД. Пример:
CREATE TABLE <table_name1> (
<column_name1><column_type1>,
<column_name2><column_type2>,
<column_name3><column_type3>
PRIMARY KEY(<column_name1>),
FOREIGN KEY(<column_name2>) REFERENCES <table_name2>(<column_name2>)
);
В коде также приведены команды, вносящие определенные ограничения для конкретных столбцов для создаваемой таблицы:
- Запрещается заполнение ячеек значениями NULL.
- Конструкция PRIMARY KEY(column_name1, column_name2, …) определяет первичный ключ.
- Конструкция FOREIGN KEY(column_namex1, …, column_namexn) REFERENCES table_name(column_namex1, …, column_namexn) определяет внешний ключ.
Дарим скидку от 60%
на обучение «Разработчик» до 27 апреля
Уже через 9 месяцев сможете устроиться на работу с доходом от 150 000 рублей
Забронировать скидку
Допускается создание нескольких первичных ключей, которые в итоге образуют один составной первичный ключ.
Покажем это на очередном примере:
CREATE TABLE instructor (
ID CHAR(5),
name VARCHAR(20) NOT NULL,
dept_name VARCHAR(20),
salary NUMERIC(8,2),
PRIMARY KEY (ID),
FOREIGN KEY (dept_name) REFERENCES department(dept_name)
);
- DESCRIBE <table_name> — просмотр различных параметров столбцов рассматриваемой таблицы (допустимый тип значений, наличие флага «ключ» и т. п.)
- INSERT INTO <table_name> — добавление в указанную таблицу новых данных
Только до 24.04
Скачай подборку материалов, чтобы гарантированно найти работу в IT за 14 дней
Список документов:
ТОП-100 площадок для поиска работы от GeekBrains
20 профессий 2023 года, с доходом от 150 000 рублей
Чек-лист «Как успешно пройти собеседование»
Чтобы получить файл, укажите e-mail:
Введите e-mail, чтобы получить доступ к документам
Подтвердите, что вы не робот,
указав номер телефона:
Введите телефон, чтобы получить доступ к документам
Уже скачали 52300
Пример:
INSERT INTO <table_name> (<column_name1>, <column_name2>, <column_name3>, …)
VALUES (<value1>, <value2>, <value3>, …);
Указание имен столбцов здесь не является обязательным.
INSERT INTO <table_name>
VALUES (<value1>, <value2>, <value3>, …);
- UPDATE <table_name> — обновление данных в указанной таблице.
UPDATE <table_name>
SET <col_name1> = <value1>, <col_name2> = <value2>, …
WHERE <condition>;
- DELETE FROM <table_name> — удаление данных из указанной таблицы.
- DROP TABLE — удаление всей таблицы

Ниже будут приведены команды для непосредственной обработки данных.
- SELECT — вывод данных из указанной таблицы
Для получения данных из конкретных столбцов:
SELECT <column_name1>, <column_name2>, …
FROM <table_name>;
Для получения всех данных из таблицы:
SELECT * FROM <table_name>;
- SELECTDISTINCT — вывод неповторяющихся значений из указанной таблицы
Для получения данных из конкретных столбцов:
SELECT DISTINCT <column_name1>, <column_name2>, …
FROM <table_name>;
Читайте также!
Автоматизированная система базы данных: хранение и использование информации

- WHERE — условный оператор
SELECT <column_name1>, <column_name2>, …
FROM <table_name>
WHERE <condition>;
В качестве условия могут быть результаты сравнения чисел, текста или логических операций (AND, OR, NOT)
- GROUP BY — группировка результатов для вывода, зачастую с использованием агрегатных функций ( COUNT, MAX, MIN, SUM, AVG)
SELECT <column_name1>, <column_name2>, …
FROM <table_name>
GROUP BY <column_namex>;
- HAVING — аналог ключевого слова WHERE специально для работы с агрегатными функциями
SELECT <column_name1>, <column_name2>, …
FROM <table_name>
GROUP BY <column_namex>
HAVING <condition>
- ORDER BY — сортировка результатов запроса
Значения сортируются по возрастанию, если явно не указан оператор сортировки ASC или DESC.
SELECT <column_name1>, <column_name2>, …
FROM <table_name>
ORDER BY <column_name1>, <column_name2>, … ASC|DESC;
- BETWEEN — оператор задания диапазона, из которого выбираются значения
Допускается задавать числа, текст и даты.
SELECT <column_name1>, <column_name2>, …
FROM <table_name>
WHERE <column_namex> BETWEEN <value1> AND <value2>;
- LIKE — дополнительный оператор условия WHERE, задающий шаблон поиска похожего значения
Здесь можно указывать условия для выбора одного символа (_) либо для выбора любого количества символов (%).
SELECT <column_name1>, <column_name2>, …
FROM <table_name>
WHERE <column_namex> LIKE <pattern>;
- IN — дополнительный оператор условия WHERE для указания нескольких значений
SELECT <column_name1>, <column_name2>, …
FROM <table_name>
WHERE <column_namen> IN (<value1>, <value2>, …);
- JOIN — связывание нескольких таблиц через общие атрибуты
В SQL существует несколько способов такого объединения.
SELECT <column_name1>, <column_name2>, …
FROM <table_name1>
JOIN <table_name2>
ON <table_name1.column_namex> = <table2.column_namex>;
- CREATE VIEW — создание виртуальной таблицы для отображения самой актуальной информации из БД
Своими столбцами и строками такая таблица напоминает обычную.

CREATE VIEW <view_name> AS
SELECT <column_name1>, <column_name2>, …
FROM <table_name>
WHERE <condition>;
Удалить виртуальную таблицу можно аналогичной командой:
DROP VIEW <view_name>;
- Агрегатные функции
Выведем эти команды в отдельную группу. Эти функции предназначены для получения какого-то общего результата после операций с данными.
- MAX(column_name) — возврат наибольшего значения из указанного столбца;
- MIN(column_name) — возврат наименьшего значения из указанного столбца;
- AVG(column_name) — возврат среднего значения указанного столбца;
- SUM(column_name) — возврат суммы значений в указанном столбце;
- COUNT(column_name) — возврат количества строк.
Читайте также!
Ошибка установки соединения с базой данных: причины возникновения и способы устранения

- Вложенные запросы
К ним относятся результаты команд SELECT, FROM и WHERE, вложенных в запрос более верхнего уровня.
Итак, подытожим. Язык SQL предназначен для взаимодействия с реляционными БД. Средствами этого языка выполняется получение доступа к базам данных, добавление новых данных или изменение имеющихся.
Любой программный код при работе с БД использует SQL-запросы, даже если это явно не видно. Например, вместо открытого запроса может использоваться специальная библиотека, превращающая исходный код на другом языке в соответствующий SQL-код и затем выполняющая его. В той же Java подобных библиотек существует достаточно много. Подводя итоги, можно сказать, что работа с базами данных SQL для новичков в особенности очень важна, поскольку эти знания потом пригодятся везде.