

Бывают ситуации, когда нужно автоматизировать сбор и анализ данных из разных источников. Например, если хочется мониторить курс рубля в режиме реального времени. Для решения подобных задач применяют парсинг.
В этой статье кратко рассказываем, как парсить данные веб-сайтов с помощью Python. Пособие подойдет новичкам и продолжающим — сохраняйте статью в закладки и задавайте вопросы в комментариях. Подробности под катом!
Дисклеймер: в статье рассмотрена только основная теория. На практике встречаются нюансы, когда нужно, например, декодировать спаршенные данные, настроить работу программы через xPath или даже задействовать компьютерное зрение. Обо всем этом — в следующих статьях, если тема окажется интересной.
Что такое парсинг?
Парсинг — это процесс сбора, обработки и анализа данных. В качестве их источника может выступать веб-сайт.
Парсить веб-сайты можно несколькими способами — с помощью простых запросов сторонней программы и полноценной эмуляции работы браузера. Рассмотрим первый метод подробнее.

Парсинг с помощью HTTP-запросов
Суть метода в том, чтобы отправить запрос на нужный ресурс и получить в ответ веб-страницу. Ресурсом может быть как простой лендинг, так и полноценная, например, социальная сеть. В общем, все то, что умеет «отдавать» веб-сервер в ответ на HTTP-запросы.

Чтобы сымитировать запрос от реального пользователя, вместе с ним нужно отправить на веб-сервер специальные заголовки — User-Agent, Accept, Accept-Encoding, Accept-Language, Cache-Control и Connection. Их вы можете увидеть, если откроете веб-инспектор своего браузера.

Наиболее подробно о HTTP-запросах, заголовках и их классификации мы рассказали в отдельной статье.
Подготовка заголовков
На самом деле, необязательно отправлять с запросом все заголовки. В большинстве случаев достаточно User-Agent и Accept. Первый заголовок поможет сымитировать, что мы реальный пользователь, который работает из браузера. Второй — укажет, что мы хотим получить от веб-сервера гипертекстовую разметку.
st_accept = "text/html" # говорим веб-серверу,
# что хотим получить html
# имитируем подключение через браузер Mozilla на macOS
st_useragent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 12_3_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.4 Safari/605.1.15"
# формируем хеш заголовков
headers = {
"Accept": st_accept,
"User-Agent": st_useragent
}
После формирования заголовков нужно отправить запрос и сохранить страницу из ответа веб-сервера. Это можно сделать с помощью нескольких библиотек: Requests, ScraPy или PySpider.
Requests: получаем страницу по запросу
Для начала работы будет достаточно Requests — он удобнее и проще, чем привычный модуль urllib.
Requests — это библиотека на базе встроенного пакета urllib, которая позволяет легко отправлять различные веб-запросы, а также управлять кукисами и сессиями, авторизацией и автоматической организацией пула соединений.
Для примера попробуем спарсить страницу с курсами в Академии Selectel — это можно сделать за несколько действий:
# импортируем модуль
import requests
…
# отправляем запрос с заголовками по нужному адресу
req = requests.get("https://selectel.ru/blog/courses/", headers)
# считываем текст HTML-документа
src = req.text
print(src)
Пример: парсинг страницы с курсами в Академии Selectel.
Сервер вернет html-страницу, который можно прочитать с помощью атрибута text.
<!doctype html>
<html data-n-head-ssr lang="ru">
<head>
…
<title>Курсы - Блог компании Селектел</title>
<meta property="og:locale" content="ru_RU" />
<meta property="og:type" content="website" />
<meta property="og:title" content="Курсы - Блог компании Селектел" />
…
Супер — гипертекстовую разметку страницы с курсами получили. Но что делать дальше и как извлечь из этого многообразия полезные данные? Для этого нужно применить некий «парсер для выборки данных».
Beautiful Soup: извлекаем данные из HTML
Извлечь полезные данные из полученной html-страницы можно с помощью библиотеки Beautiful Soup.
Beautiful Soup — это, по сути, анализатор и конвертер содержимого html- и xml-документов. С помощью него полученную гипертекстовую разметку можно преобразовать в полноценные объекты, атрибуты которых — теги в html.
# импортируем модуль
from bs4 import BeautifulSoup
…
# инициализируем html-код страницы
soup = BeautifulSoup(src, 'lxml')
# считываем заголовок страницы
title = soup.title.string
print(title)
# Программа выведет: Курсы - Блог компании Селектел
Готово. У нас получилось спарсить и напечатать заголовок страницы. Где это можно применить — решать только вам. Например, мы в Selecte на базе Requests и Beautiful Soup разработали парсер данных с Хабра. Он помогает собирать и анализировать статистику по выбранным хабраблогам. Подробнее о решении можно почитать в предыдущей статье.
Проблема парсинга с помощью HTTP-запросов
Бывают ситуации, когда с помощью простых веб-запросов не получается спарсить все данные со страницы. Например, если часть контента подгружается с помощью API и JavaScript. Тогда сайт можно спарсить только через эмуляцию работы браузера.
Интересен Python? Мы собрали самые интересные и популярные запросы разработчиков в одном файле! По ссылке — материалы по геймдеву, машинному обучению, программированию микроконтроллеров и графических интерфейсов.
Парсинг с помощью эмулятора
Для эмуляции работы браузера необходимо написать программу, которая будет как человек открывать нужные веб-страницы, взаимодействовать с элементами с помощью курсора, искать и записывать ценные данные. Такой алгоритм можно организовать с помощью библиотеки Selenium.
Настройка рабочего окружения
1. Установите ChromeDriver — именно с ним будет взаимодействовать Selenium. Если вы хотите, чтобы актуальная версия ChromeDriver подтягивалась автоматически, воспользуйтесь webdriver-manager. Далее импортируйте Selenium и необходимые зависимости.
pip3 install selenium
from selenium import webdriver as wd
2. Инициализируйте ChromeDriver. В качестве executable_path укажите путь до установленного драйвера.
browser = wd.Chrome("/usr/bin/chromedriver/")
Теперь попробуем решить задачу: найдем в Академии Selectel статьи о Git.
Задача: работа с динамическим поиском
При переходе на страницу Академии встречает общая лента, в которой собраны материалы для технических специалистов. Они помогают прокачивать навыки и быть в курсе новинок из мира IT.

Но материалов много, а у нас задача — найти все статьи, связанные с Git. Подойдем к парсингу системно и разобьем его на два этапа.
Шаг 1. Планирование
Для начала нужно продумать, с какими элементами должна взаимодействовать наша программа, чтобы найти статьи. Но здесь все просто: в рамках задачи Selenium должен кликнуть на кнопку поиска, ввести поисковый запрос и отобрать полезные статьи.

Теперь скопируем названия классов html-элементов и напишем скрипт!
Шаг 2. Работа с полем ввода
Работа с html-элементами сводится к нескольким пунктам: регистрации объектов и запуску действий, которые будет имитировать Selenium.
...
# регистрируем кнопку "Поиск" и имитируем нажатие
open_search = browser.find_element_by_class_name("header_search")
open_search.click()
# регистрируем текстовое поле и имитируем ввод строки "Git"
search = browser.find_element_by_class_name("search-modal_input")
search.send_keys("Git")
Осталось запустить скрипт и проверить, как он отрабатывает:

Скрипт работает корректно — осталось вывести результат.
Шаг 3. Чтение ссылок и результат
Вне зависимости от того, какая у вас задача, если вы работаете с Requests и Selenium, Beautiful Soup станет серебряной пулей в обоих случаях. С помощью этой библиотеки мы извлечем полезные данные из полученной гипертекстовой разметки.
from bs4 import BeautifulSoup
...
# ставим на паузу, чтобы страница прогрузилась
time.sleep(3)
# загружаем страницу и извлекаем ссылки через атрибут rel
soup = BeautifulSoup(browser.page_source, 'lxml')
all_publications = \
soup.find_all('a', {'rel': 'noreferrer noopener'})[1:5]
# форматируем результат
for article in all_publications:
print(article['href'])
Готово — программа работает и выводит ссылки на статьи о Git. При клике по ссылкам открываются соответветствующие страницы в Академии Selectel.

Полезные материалы для Python-разработчиков
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Какому инструменту для парсинга отдаете предпочтение?
6.79% Напишу свой вариант в комментариях11
Проголосовали 162 пользователя. Воздержались 48 пользователей.

В современном мире цифровых технологий умение извлекать данные из интернета становится всё более важным. Эти навыки позволяют получить актуальную информацию, которая может помочь в исследованиях, бизнесе и других сферах деятельности. Сегодня мы рассмотрим процесс извлечения данных, который не требует углубленных технических знаний.
Эффективность в достижении целей в значительной степени зависит от оптимального подхода к обработке больших объемов информации. В процессе структурирования данных можно использовать различные инструменты, в том числе и сценарии. С их помощью можно автоматизировать рутинные задачи и обеспечить быструю обработку данных.
Веб-технологии становятся адаптивными к разнообразным запросам пользователей. Основы понимания веб-структуры и принципы взаимодействия с сетевыми ресурсами позволяют выполнять парсинг данных с минимальными затратами времени и усилий. Даже неопытные разработчики могут освоить этот процесс, следуя простым инструкциям и рекомендуемым практикам.
Простота и эффективность современных библиотек делают процесс сбора данных доступным практически каждому. Достаточно лишь немного практики и осведомлённости, чтобы начать извлекать полезную информацию из многочисленных веб-источников. Ниже представлен пример минимального кода на одном из самых популярных языков для данных целей:
import requests from bs4 import BeautifulSoup url = https://example.com response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser') data = soup.find_all('h2') for item in data: print(item.text)
Задействовав указанную технологию, можно заметить, насколько быстрым и удобным становится работа с интернет-данными. Компактность и мощность решения позволяют внедрить его в различные проекты, добавляя ценность и ускоряя процессы обработки информации.
Основы парсинга на Python
Анализ веб-страниц активно применяется в различных областях: от автоматического сбора данных до мониторинга конкурентных сайтов. Чтобы приступить к этой задаче, необходимо освоить принцип извлечения информации, которая скрыта в разметке HTML. С помощью доступных библиотек на языке, можно значительно упростить эту задачу, предоставляя мощные инструменты для работы с интернет-ресурсами.
Один из главных элементов при анализе данных с веба – это умение разбираться с HTML-структурой документа. Библиотеки, такие как BeautifulSoup, предоставляют средства для поиска элементов внутри этого сложного лабиринта. Они используют иерархическую модель, что позволяет выбирать и извлекать нужную информацию.
Для начала важно импортировать необходимые модули. Например, следует импортировать requests для загрузки страницы:
import requests
Затем стоит воспользоваться инструментом для обработки и структурирования данных:
from bs4 import BeautifulSoup
Следующим шагом будет отправка GET-запроса к нужному ресурсу и создание супа для анализа:
url = 'https://example.com' response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser')
После этого можно приступать к извлечению информации, используя различные методы, такие как find или find_all, которые облегчают навигацию по HTML-документу и поиск данных.
Мир парсинга богат возможностями и предоставляет обширный спектр инструментов для эффективного извлечения данных. Начав с базового понимания, можно развиваться и адаптировать полученные знания под собственные нужды, создавая комплексные решения для работы с данными из интернета.
Установка необходимых библиотек
Наиболее востребованными библиотеками, которые облегчают работу с интернет-страницами, являются:
| Библиотека | Назначение |
|---|---|
| requests | Отправка HTTP-запросов и получение ответов от веб-сайтов |
| beautifulsoup4 | Анализ и разбор HTML/XML документов |
| lxml | Высокопроизводительный парсер XML и HTML |
Для установки этих библиотек используйте систему управления пакетами pip. Это можно сделать, выполнив команды в терминале, как показано ниже:
pip install requests beautifulsoup4 lxml
После завершения установки эти инструменты станут мощными помощниками в ваших проектах, позволяя эффективно взаимодействовать с веб-страницами и извлекать нужные данные. Эти пакеты представляют собой основу любого проекта, связанного с разбором контента сайтов. Перед началом работы убедитесь, что все модули установлены правильно и доступны для использования в вашем коде.
Выбор целевой информации
Для начала проанализируйте структуру веб-сайта. Различные элементы сайта, такие как заголовки, списки, таблицы и ссылки, могут содержать полезные сведения. Использование инструментов для анализа HTML-кода страницы, таких как браузерные расширения, поможет определить основу для дальнейших действий.
При работе с выбранной информацией важно учитывать формат данных. Текстовые блоки, изображения, ссылки или таблицы – у каждого типа есть свои особенности для извлечения. Удостоверьтесь в корректности разметки и наличии повторяющихся элементов, избегайте ошибок, которые могут возникнуть при извлечении некорректных данных.
Рассмотрим пример извлечения заголовков новостей с веб-сайта. Используя модуль BeautifulSoup для работы с разметкой, временно сохраняем содержимое страницы и извлекаем нужные элементы:
from bs4 import BeautifulSoup import requests response = requests.get('https://news.example.com') soup = BeautifulSoup(response.text, 'html.parser') # Извлечение всех заголовков с классом 'headline' headlines = soup.find_all('h2', class_='headline') for headline in headlines: print(headline.text)
Этот пример демонстрирует, как с помощью BeautifulSoup можно выбрать нужные узлы и обратиться к их содержимому. Анализ кода HTML и идентификация элементов поможет в дальнейшей настройке процесса извлечения. Таким образом, сосредоточьтесь на данных, которые имеют для вас значение.
Создание структуры парсера
Стартуем с инициализации главного модуля, где сосредоточены ключевые элементы: импортирование библиотек, настройка параметров и распределение логических блоков. Здесь важно определить общую архитектуру, которая обеспечит гибкость и адаптивность вашего решения. Обратите внимание на импорт необходимых библиотек, таких как requests для сетевых запросов и BeautifulSoup для обработки HTML-структур.
Следующий шаг – создание функций для получения и обработки HTML-кода сайта. Главная функция выполняет запрос и возвращает содержимое страницы, чтобы в дальнейшем применить к нему методичную фильтрацию и извлечение целевых данных. Например:
def fetch_page(url): response = requests.get(url) if response.status_code == 200: return response.text return None
На этом этапе важно предусмотреть обработку ошибок, чтобы парсер корректно реагировал на возможные сбои или изменения на веб-странице. Включите механизмы логирования и попыток повторного запроса в случае неверного ответа от сервера.
Последующий этап включает разработку систематизированных функций для обработки и анализа структурированных данных. Используйте инструменты для парсинга HTML, такие как BeautifulSoup, чтобы изолировать элементы, представляющие интерес. Например, извлечение данных может выглядеть следующим образом:
def extract_data(html_content): soup = BeautifulSoup(html_content, 'html.parser') return soup.find_all('div', class_='target-class')
Структурирование итоговой информации также требует внимания – конечный продукт должен быть удобным для дальнейшего использования и анализа. Используйте форматы, позволяющие легко хранить и обрабатывать данные, будь то JSON, CSV или база данных.
Завершаем проект созданием основного скрипта, который интегрирует все части и запускает процесс. Эффективная структура делает приложение масштабируемым и легко модифицируемым, что позволит адаптироваться к изменениям в веб-данных.
Обработка и фильтрация данных
В задачах, связанных с извлечением информации с веб-сайтов, крайне важно уделить внимание обработке и фильтрации данных. Это обеспечивает точное получение информации и минимизирует загрязнение некорректными данными. Зачастую ресурсы сети содержат множество лишнего контента, поэтому отбор необходимой информации становится ключевым этапом.
Обработка данных включает в себя несколько последовательных шагов:
- Очистка информации. Необходимо удалить все лишние пробелы, символы-разделители и другой нежелательный контент, который может мешать работе алгоритмов анализа. Для этого могут быть полезны методы строк и регулярные выражения. Например:
import re
text = Пример! текста, с лишними символами.
clean_text = re.sub(r'[^\w\s]', '', text)- Преобразование форматов. Преобразуйте данные в удобные для анализа структуры, такие как списки или словари. Это упрощает дальнейшую работу с ними, например, через модули
jsonилиcsv: import json
json_data = '{ключ: значение}'
parsed_data = json.loads(json_data)
Фильтрация играет важную роль в извлечении ценной информации из массива данных. Зачастую используется для отбора данных по ключевым критериям или удаления дублирующей информации. Рассмотрим пример, где осуществляется фильтрация с применением ключевых слов:
- Использование условий отбора. Применяйте условия, чтобы выделить только те данные, которые соответствуют определенным требованиям или критериям. Например, фильтрация списка по ключевым словам:
data = [новости, статья, блог, веб-сайт]
keywords = [статья, блог]
filtered_data = [item for item in data if item in keywords]
Современные библиотеки предоставляют широкий спектр инструментов для обработки больших объемов информации. Использование их функционала ускоряет и упрощает извлечение и анализ целевых данных. Применение данных методов значительно повысит надежность и эффективность вашего решения, позволяя сократить количество ошибок и повысить качество полученной информации.
Автоматизация и оптимизация кода
Одной из основ оптимизации является правильное использование библиотек и фреймворков. Они могут значительно облегчить задачу взаимодействия с веб-ресурсами, сделав процесс парсинга более интуитивным. Настоятельно рекомендуется отдавать предпочтение библиотекам, оптимизированным для работы с сетевыми запросами и структурированными данными.
Важным аспектом является повторное использование кода. Этот подход способствует уменьшению количества ошибок, а также улучшает читаемость и поддержку вашего кода. Для этого можно выделить в отдельные функции те части логики, которые могут понадобиться неоднократно, например, обработку ошибок или извлечение данных из определенной веб-страницы. Пример функции для повторного использования:
def extract_data_from_site(url): # Использование библиотеки requests для получения данных с сайта response = requests.get(url) # Проверка успешности запроса if response.status_code == 200: # Возврат содержимого страницы return response.content else: # Логгирование ошибки log_error(fОшибка доступа к {url}) return None
Оптимизация также включает в себя кеширование данных, что снижает нагрузку на сеть и ускоряет получение повторно запрашиваемой информации. Это особенно полезно при обращении к ресурсоемким сайтам. Использование сторонних библиотек для кеширования таких как requests-cache может значительно снизить количество запросов и повысить общую производительность вашего скрипта.
Следует также уделить внимание обработке ошибок и недопущению аварийного завершения работы. Обернув ключевые участки кода в блоки try-except, вы сможете плавно предугадать и обработать возможные исключения, улучшая надежность вашего инструмента. Логгирование ошибок поможет при дальнейшей отладке и оптимизации.
try: data = extract_data_from_site(https://example.com) process_data(data) except Exception as e: log_error(fОшибка обработки данных: {str(e)})
Подводя итог, для достижения максимальной эффективности работы при обработке данных с сайта, важно выбирать правильные инструменты, поддерживать чистоту и модульность кода, использовать механизмы кеширования, а также своевременно обрабатывать возможные ошибки. Все это нацелено на создание продукта, который будет выполнять поставленные задачи с максимальной продуктивностью и надежностью.
Комментарии
С помощью парсинга можно быстро и эффективно собирать информацию с веб-сайтов. В этой статье разберемся, как работает этот процесс, рассмотрим полезные библиотеки и инструменты и научимся парсить сайты на Python.
Что такое парсинг?
Парсинг (англ. parsing — разбор) — это процесс автоматического анализа веб-сайтов для сбора структурированной информации. Еще парсинг часто называют веб-скрапингом. Представьте, что вы ищете на новостном сайте статьи про Python и сохраняете каждую в заметки: копируете заголовок и ссылку. С помощью парсинга можно автоматизировать этот процесс. Все данные будет искать и сохранять скрипт, а вам останется только проверять файл с результатами.
Часто парсинг используют боты, которые потом предоставляют доступ к собранным структурированным данным. Это может быть список статей на сайте, вакансий на платформе по поиску работы или предложений на досках объявлений. Например, один из героев нашего блога написал бот, который нашел ему работу за месяц. Если у сайта нет полноценного открытого API, то парсер ищет данные с помощью GET-запросов к серверу, а это создает дополнительную нагрузку на сервер.
Это накладывает некоторые этические ограничения на скрипты для парсинга веб-сайтов:
- не стоит отправлять слишком много запросов к серверу, главная задача — собрать полезные данные, а не положить инфраструктуру сервиса;
- если есть публичное API, то лучше использовать его;
- на сайте могут быть личные данные пользователей, к ним надо относиться бережно и внимательно.
Надо быть готовым к тому, что некоторые владельцы веб-сайтов ограничивают парсинг и пытаются с ним бороться. В этих случаях приходится смириться с политикой сервиса или использовать более продвинутых ботов, которые имитируют поведение пользователя и получают доступ к странице через собственный экземпляр браузера. Этот способ сложнее, чем отправка запроса на сервер, но надежнее.
Для чего нужен парсинг?
С помощью парсинга можно быстро собрать сразу много данных, а не тратить время на ручное исследование веб-сайтов. В некоторых задачах именно время является ключевым фактором для перехода к автоматизации. Вот сферы, в которых обычно применяют веб-парсинг:
- Мониторинг цен. Можно быстро и эффективно отслеживать цены на один и тот же товар на разных площадках. Пользователям эта информация нужна для поиска самого выгодного предложения, а компаниям — для корректировки цен в своих магазинах.
- Отслеживание трендов. В социальных сетях постоянно меняются популярные темы. Надо проводить много времени в Сети, чтобы идти в ногу со временем или использовать автоматизированные системы сбора популярных постов.
- Новости. С помощью парсинга можно разработать собственный агрегатор новостей и настроить его только на интересные сайты и медиа.
- Исследования. Для глубокого анализа рынка или конкурентов нужны большие массивы данных. Ручной сбор займет много времени. Парсер выполнит задачу быстрее и точно ничего не пропустит.
Python и Beautiful Soup
Для парсинга удобно использовать Python из-за его простого синтаксиса и интерпретируемого подхода. Скрипты можно писать быстро и не собирать весь проект снова после незначительных изменений в коде. Разработанный парсер можно без проблем перенести практически на любую платформу или запустить в облаке, автоматизировав процесс хранения информации.
Еще одно преимущество Python — его популярность. Для языка программирования есть большое количество сторонних библиотек для различных задач и активное сообщество, которое может помочь советом. Одна из полезных библиотек для парсинга веб-сайтов — BeautifulSoup. С ее помощью можно легко анализировать HTML-файлы и находить в них нужные данные. В этой статье будем парсить сайт с ее помощью.
Как установить Beautiful Soup
Есть несколько популярных способов запуска кода на Python:
- На своем компьютере. Python работает на Windows, Linux и macOS. Для этого надо предварительно установить язык программирования на устройство. Сам код можно писать в редакторе или в полноценной IDE. Из бесплатных доступны Visual Studio Code и PyCharm Community. Плюсы этого способа заключаются в том, что все данные хранятся локально, а код выполняется быстрее.
- В облачном сервисе. Есть множество платформ, которые позволяют писать и запускать код на Python в облаке. Для этого на компьютер не надо устанавливать дополнительные пакеты и заботиться о совместимости. Понадобится только браузер и стабильное подключение к интернету. Все данные будут передаваться на удаленный сервер. Такой способ подходит для новичков или для быстрых экспериментов с кодом. Можно использовать бесплатные Repl.it, Google Colab или Programiz.
Для работы нам понадобятся библиотеки BeautifulSoup, requests и lxml. Их можно установить с помощью следующей команды в терминале:
$ pip3 install requests BeautifulSoup4 lxml
Получаем HTML-страницу
Для начала парсинга надо получить страницу, из которой будем вытаскивать полезные данные. Для этого будем использовать библиотеку requests, чтобы отправить GET-запрос, в качестве ответа получить код страницы и сохранить его. Попробуем распарсить вот эту статью, получив заголовок и первый абзац. Код выглядит следующим образом:
import requests url = 'https://blog.skillfactory.ru/programmist-v-sims-4/' response = requests.get(url) response.raise_for_status() print(response.text)
Что в коде:
- import requests — импортируем библиотеку requests в код скрипта;
- url = ‘https://blog.skillfactory.ru/programmist-v-sims-4/’ — переменная, в которой хранится ссылка на целевую страницу;
- response = requests.get(url) — выполняем GET-запрос и передаем в него переменную с хранящейся ссылкой;
- response.raise_for_status() — эта функция вернет нам код ошибки, если запрос не получится выполнить. Если не добавить эту строчку, то Python будет дальше выполнять код и не обращать внимания на ошибку;
- print(response.text) — печатаем код полученной страницы.
В ответе мы получим весь код страницы, включая CSS-стили и JavaScript. Вот так это выглядит:
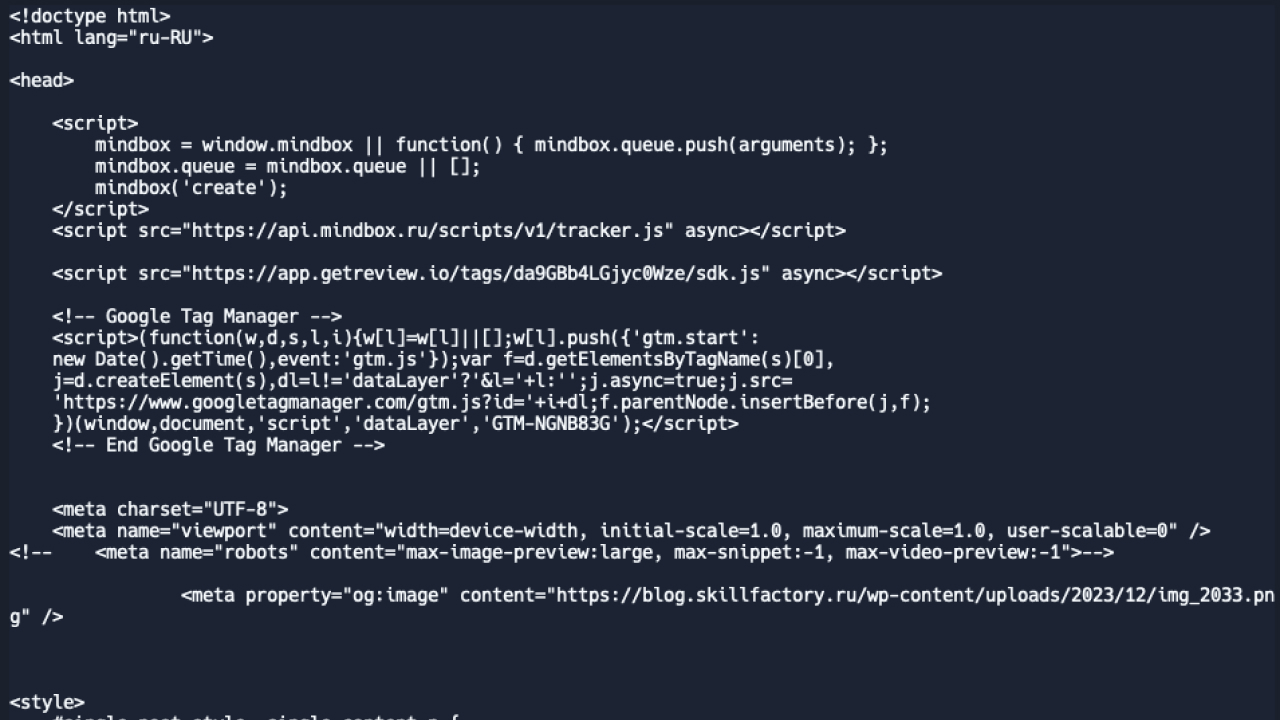
Парсим страницу
Код страницы у нас уже есть, но теперь из него надо получить полезные данные. Обозначим, что для решения нашей задачи необходимо получить заголовок статьи и первый абзац. Для этого понадобятся возможности библиотеки BeautifulSoup. Но сперва надо найти теги элементов, которые будем извлекать из кода страницы.
Для этого потребуется веб-инспектор в любом браузере. Мы будем использовать Safari, но этот режим есть и в других браузерах. К примеру, в Google Chrome он открывается сочетанием клавиш Сtrl + Shift + I (Windows) или ⌥ + ⌘ + I (macOS). После этого можно выбрать на странице элемент и увидеть его код в инспекторе.
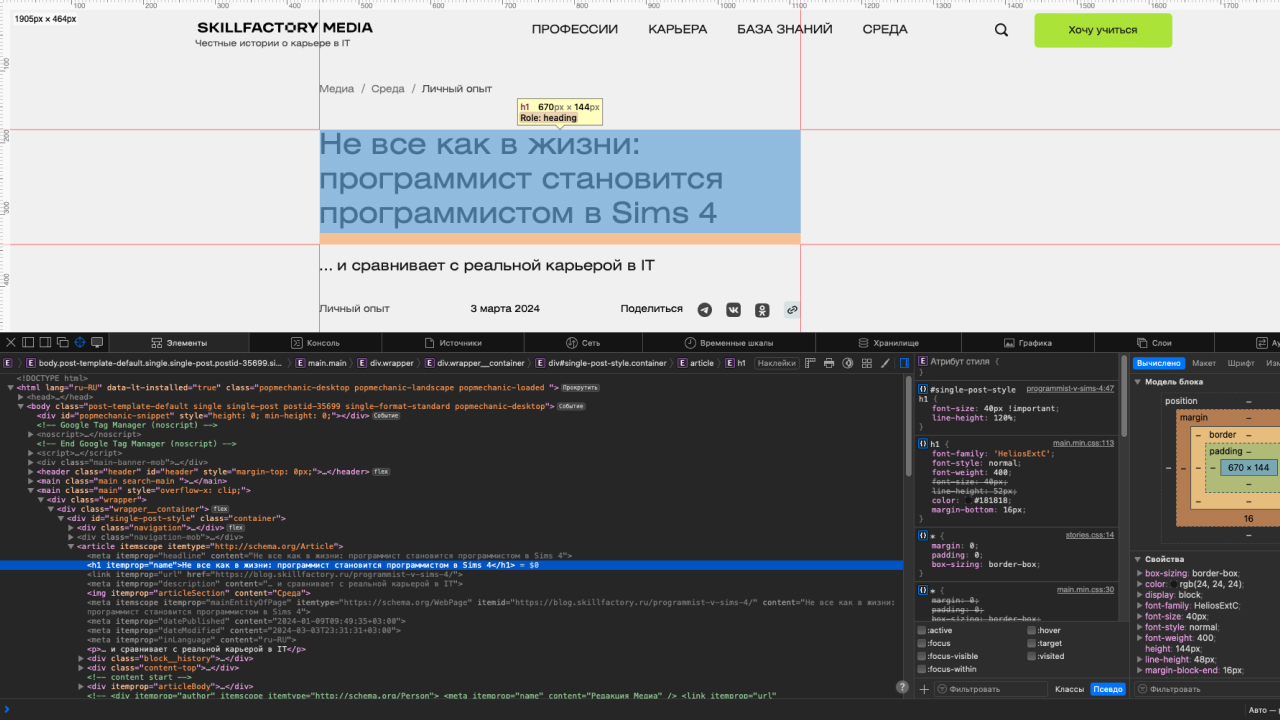
Заголовок статьи находится в теге <h1>, поэтому попробуем получить его содержимое с помощью библиотеки BeautifulSoup. Для этого передадим в функцию find искомый тег:
from bs4 import BeautifulSoup
import requests
url = 'https://blog.skillfactory.ru/programmist-v-sims-4/'
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'lxml')
title = soup.find('h1')print(title)
>>> <h1 itemprop="name">Не все как в жизни: программист становится программистом в Sims 4</h1>
Все получилось и Python вывел в консоль текст заголовка, но с тегами. Надо избавиться от них. Это можно сделать с помощью преобразования содержимого переменной title в текст. После этого Python удалит теги, оставив только их содержимое:
soup = BeautifulSoup(response.text, 'lxml')
title = soup.find('h1')
title = title.text
print(title)
>>> Не все как в жизни: программист становится программистом в Sims 4
Теперь надо повторить весь порядок действий для вывода первого абзаца. Начинаем с поиска тега в инспекторе и после этого вытаскиваем его из файла и преобразуем в текст.
paragraph = soup.find('p')
paragraph = paragraph.text
print(paragraph)
>>> Честные истории о карьере в IT
Мы в точности повторили весь порядок действий, но парсер вывел совсем не ту строчку. Все дело в том, что мы искали элемент по тегу <p>. В HTML-файле их может быть несколько, а BeautifulSoup ищет самый первый. Поэтому запрос надо уточнить и сделать его более конкретным.
Для этого можно указать дерево наследования элементов. К примеру, если тег <p> входит в <article>, а тот — в <main>, то код запроса можно будет записать так: soup.find(‘main’).find(‘article’).find(‘p’). Еще можно искать элемент по его классу. Для этого в функцию надо передать тег и его класс: soup.find(‘p’, class_=’paragraph’).
В нашем случае запрос будет выглядеть следующим образом:
paragraph = soup.find('div', class_='single-content').find('p')
paragraph = paragraph.text
print(paragraph)
>>> Sims 4 — детальный симулятор жизни, в котором можно стать кем угодно. В игре приходится сталкиваться с трудностями, переживать неудачи и двигаться по карьерной лестнице. В этой статье попробуем с полного нуля стать программистом и развиваться как разработчик.
Таким образом можно распарсить любую веб-страницу и получить необходимые данные, а потом использовать их по своему усмотрению. К примеру, строить график изменения цен на товары в онлайн-магазинах или автоматически отправлять ссылки на новые статьи с кратким содержанием в Telegram.
Сохраняем результат
Сейчас наш код выводит результат парсинга веб-страницы в консоль. Эти данные никуда не сохраняются и к ним сложно получить доступ. Для этого каждый раз надо будет запускать скрипт. Упростим задачу и запишем данные в файл.
Для этого воспользуемся встроенной функцией write(). Сперва откроем файл в режиме записи:
file = open("parsing.txt", "w")
Если файла с таким названием нет, то Python сам создаст его в директории проекта.
После этого запишем данные, полученные во время парсинга, и обязательно закроем файл:
file.write(title) file.write(paragraph) file.close()
Коротко о том, как парсить сайты на Python
- С помощью парсинга можно автоматически анализировать веб-страницы и вытаскивать из них полезную информацию.
- Для парсинга необходимо отправлять запросы к серверу, чтобы получать код сайтов, а это может нагружать сервис, поэтому важно не злоупотреблять этим.
- Если у сервиса есть публичное API, то лучше пользоваться им.
- В Python удобно парсить веб-сайты с помощью библиотеки BeautifulSoup.
- Запросы выполняются с помощью библиотеки requests.
- Результат парсинга можно сохранять в файл, вносить в базу данных или отправлять с помощью почты и мессенджеров.
Парсинг сайтов на Python автоматизирует сбор информации с сайтов — от цен конкурентов до контактов потенциальных клиентов. Для этого используются две основные библиотеки: BeautifulSoup подходит для простых задач и небольших проектов, а Scrapy — для масштабного парсинга данных.
Чтобы использовать эти инструменты, вспомним основы HTML, DOM-дерева и принципы работы динамических страниц.
Основные понятия парсинга данных
HTML-документ — это текстовый файл с расширением .html. Он содержит набор элементов для отображения страницы в браузере.
Структура HTML-документа состоит из двух частей: заголовка (head) и тела (body). Весь документ обрамляется корневым тегом html.
<!DOCTYPE html>
<html>
<head>
...
</head>
<body>
...
</body>
</html>
Заголовок содержит метаданные, стили, скрипты, заголовок страницы. В теле документа находятся теги и основной контент, который отображается в окне браузера.
<!DOCTYPE html>
<html>
<head>
<title>Страница с тегами</title>
<meta charset="UTF-8">
<link rel="stylesheet" href="styles.css">
</head>
<body>
<header>
<nav>
<a href="#">Главная</a>
<a href="#">О нас</a>
</nav>
</header>
<main>
<h1>Заголовок статьи</h1>
<p>Первый абзац текста</p>
<p>Второй абзац текста</p>
<div class="clicker">
<img src="image.jpg" alt="Картинка">
<button onclick="alert('Клик!')">Нажми меня</button>
</div>
</main>
<footer>
<p>Контакты разработчика</p>
</footer>
</body>
</html>
DOM-дерево — это представление HTML-документа в виде древовидной структуры объектов. Каждый элемент HTML становится узлом этого дерева. Благодаря DOM можно взаимодействовать с элементами страницы через JavaScript:
- получать доступ к содержимому,
- изменять состояние тегов,
- добавлять или удалять элементы.
Корневой элемент DOM-дерева — тег html. От него идет разветвление на head и body — его прямых потомков. Остальные элементы образуют более глубокие уровни вложенности.
Тут можно посмотреть, как выглядит DOM-дерево для определенного фрагмента кода.
Статические страницы содержат фиксированный HTML. Его код не меняется после загрузки. По этой причине статические страницы проще парсить. Достаточно отправить HTTP-запрос и будет получен весь HTML-документ, из которого можно извлечь целевые теги. С этой задачей успешно справляются любые библиотеки для парсинга: Requests, BeautifulSoup, Urllib3 и другие.
Динамические страницы формируют контент с помощью JavaScript после загрузки основного HTML. Контент может подгружаться через API, изменяться при взаимодействии пользователя или обновляться автоматически.
Простой HTTP-запрос не парсит динамически загруженные сайты. Для этого нужны инструменты, эмулирующие работу браузера. Например, Selenium WebDriver. Он запускает браузер, выполняет JavaScript-код и парсит финальное DOM-дерево с динамическим контентом.
Этические и юридические аспекты парсинга данных
Парсинг не запрещен законодательством. Если ваша программа не выводит из строя сайты и не вредит бизнесу, то шансы на судебные иски стремятся к нулю.
Что можно делать:
- Собирать информацию, которая находится в открытом доступе.
- Парсить данные, не нагружая сайт и не мешая его работе.
Чего нельзя делать:
- Воровать закрытую информацию компаний.
- Собирать личные данные пользователей (телефоны, адреса, паспортные данные).
- Намеренно вредить работе сайта большим количеством запросов.
Перед сбором данных задавайте себе простой вопрос: «Мне понравится, если кто-то соберет эту информацию обо мне?» Подумайте также о том, приносит ли ваш парсинг пользу другим людям или вы делаете это только ради собственной выгоды.
Если закон разрешает какие-то действия, это не значит, что их правильно делать с моральной точки зрения. Например, технически возможно собрать все комментарии человека в соцсетях, но будет ли это этично по отношению к нему?
Cобирайте только те данные, которые действительно нужны для вашей задачи. Не нужно сохранять личную информацию людей просто потому, что вы можете это сделать.
Если собираете данные временно, например, чтобы найти фальшивые отзывы на Яндекс Картах, а потом сразу удаляете личную информацию — это более приемлемо, чем создание постоянной базы данных о людях для продажи рекламодателям.
BeautifulSoup — это библиотека Python для извлечения данных из HTML и XML. Следуйте пошаговому руководству, чтобы установить BeautifulSoup.
Откройте терминал и выполните команду:
pip install beautifulsoup4
Установите парсер lxml:
Также понадобится библиотека requests для выполнения HTTP-запросов:
Самый простой парсер на BeautifulSoup:
import requests
from bs4 import BeautifulSoup
url = 'https://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
Основные функции и методы библиотеки
Найти первый абзац:
first_paragraph = soup.find('p')
Найти все абзацы:
all_paragraphs = soup.find_all('p')
Один элемент с классом ‘content’:
content = soup.find(class_='content')
Все элементы с классом ‘content’:
all_content = soup.find_all(class_='content')
Поиск ссылки по href:
link = soup.find('a', href='https://example.com')
Поиск по нескольким атрибутам:
element = soup.find('div', attrs={'id': 'main', 'class': 'content'})
Найти все абзацы с определенным классом:
paragraphs = soup.find_all('p', class_='text-block')
Найти все ссылки внутри div с определенным id:
links = soup.find('div', id='menu').find_all('a')
Плюсы BeautifulSoup
- Простой синтаксис, поэтому библиотекой пользуются даже начинающие разработчики.
- Гибкий поиск элементов ищет теги по имени, классу, id, атрибутам. Можно комбинировать условия поиска и использовать CSS-селекторы.
- Автоматическое исправление невалидного HTML. BeautifulSoup пытается восстановить неправильную структуру документа, что полезно при работе с некачественной версткой.
- Низкие требования к ресурсам компьютера по сравнению с браузерными решениями вроде Selenium.
Недостатки BeautifulSoup
- Нет поддержки JavaScript. Библиотека работает только со статическим HTML и не может обрабатывать динамически загружаемый контент.
- Ограниченная производительность при работе с большими документами. Для парсинга крупных файлов лучше использовать потоковые парсеры.
- Отсутствие встроенной поддержки асинхронности. Для параллельной обработки нескольких страниц требуются дополнительные библиотеки asyncio и aiohttp
BeautifulSoup не подходит для парсинга сайтов с динамической загрузкой контента, высоконагруженных проектов. Для этих целей выбирайте фреймворк Scrapy.
Scrapy: мощный фреймворк для парсинга больших объемов данных
Scrapy — это фреймворк для парсинга сайтов, построенный на асинхронной архитектуре. Рассмотрим его основные компоненты.
Пауки (Spiders) — это классы, которые определяют как парсить конкретный сайт. В пауке указываются начальные URL-адреса, правила извлечения данных и переходов между страницами. Паук обходит страницы сайта и извлекает информацию с помощью CSS-селекторов или XPath-выражений.
Элементы (Items) — это контейнеры для хранения извлеченных данных. Они похожи на словари Python, но предоставляют дополнительную валидацию полей. Items определяют структуру данных, которые будут собраны пауком.
Каналы обработки (Pipelines) — это компоненты для обработки извлеченных данных. Каждый элемент проходит через цепочку pipeline-обработчиков. В pipeline можно выполнять очистку данных, удалять дубликаты, сохранять информацию в базу данных.
Парсинг HTML на Scrapy выглядит так:
- Паук отправляет запрос к сайту.
- Получает ответ и извлекает данные.
- Создает элементы с данными.
- Передает элементы в pipeline.
- Pipeline обрабатывает и сохраняет данные.
Установка и настройка Scrapy
Откройте терминал и выполните команду::
Создайте новый проект:
scrapy startproject имя_проекта
Эта команда создаст структуру каталогов — файлы настроек и шаблоны пауков.
Файл settings.py содержит основные настройки проекта. Базовые параметры, которые требуют настройки:
- USER_AGENT = ‘Mozilla/5.0…’ (идентификация парсера).
- ROBOTSTXT_OBEY = True (соблюдение правил robots.txt).
- CONCURRENT_REQUESTS = 16 (количество одновременных запросов).
- DOWNLOAD_DELAY = 1 (задержка между запросами).
- COOKIES_ENABLED = False (использование cookies).
Для создания нового паука используйте команду:
scrapy genspider имя_паука domain.com
Пример простого паука:
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['ваш_домен.com']
start_urls = ['http://ваш_домен.com']
def parse(self, response):
title = response.css('h1::text').get()
yield {'title': title}
Запуск паука выполняется командой:
Для сохранения результатов в файл:
scrapy crawl имя_паука -o результат.json
Для обработки данных перед сохранением используется pipelines.py:
class ExamplePipeline:
def process_item(self, item, spider):
item['title'] = item['title'].strip()
return item
Активация pipeline происходит в settings.py:
ITEM_PIPELINES = {
'название_проекта.pipelines.ExamplePipeline': 300
}
Плюсы Scrapy
- Обрабатывает запросы асинхронно.
- Автоматически управляет порядком обработки URL и перераспределяет нагрузку.
- Легко добавлять прокси-серверы, ротацию User-Agent, обработку ошибок.
- Встроенная поддержка экспорта в JSON, CSV, XML.
Недостатки Scrapy
- Сложность отладки асинхронного кода.
- Ограниченная поддержка JavaScript.
Сравнение BeautifulSoup и Scrapy
Выбор инструмента зависит от масштаба задачи. Для извлечения данных с нескольких страниц достаточно BeautifulSoup. Для создания поискового робота или регулярного парсинга больших объемов данных оптимальным выбором будет Scrapy.
Парсинг на Python BeautifulSoup лучше подходит для:
- Парсинга отдельных страниц.
- Небольших скриптов.
- Интеграции в существующие проекты.
BeautifulSoup дает разработчику полную свободу в организации кода и выборе дополнительных инструментов, но ограничивается только базовыми функциями извлечения данных.
Scrapy эффективнее для:
- Парсинга интернет-магазинов с тысячами товаров.
- Регулярного мониторинга цен конкурентов.
- Полноценных парсинг-проектов со сложной логикой обработки.
Фреймворк используют для масштабного сбора данных. Python Scrapy имеет встроенные механизмы для работы с прокси, управления cookies, организации очередей запросов и конвейерной обработки данных.
Продвинутые техники парсинга
Динамически загружаемый контент — это проблема при парсинге. Чтобы выгрузить целевой контент со страницы, нужно имитировать действия пользователя. Для этого часто используют Selenium. Библиотека управляет браузером — загружает страницы, выполняет JavaScript и получает доступ к DOM после его изменения.
При обработке динамического контента учитывайте задержки. JavaScript выполняется асинхронно, поэтому Selenium должен дождаться полной загрузки элементов, прежде чем пытаться с ними взаимодействовать.
Пример ожидания:
# Ожидание элемента с id="dynamic_content" (до 10 секунд)
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "dynamic_content"))
)
Еще можно использовать time.sleep, но это менее эффективно — задержка фиксирована и не зависит от скорости загрузки страницы.
Если контент загружается через AJAX, можно использовать execute_script для проверки состояния загрузки. Например, можно проверить значение переменной JavaScript, которая отслеживает состояние загрузки.
Когда контент загружается поэтапно, приходится комбинировать ожидания, execute_script и циклы для обработки всех частей динамического контента.
Работа с API
Многие сайты предоставляют API для получения данных. Это предпочтительный способ парсинга на Python. Сбор данных через API:
- не нагружает сервер излишними запросами;
- предоставляет данные в структурированном виде;
- обычно имеет официальную документацию.
Для работы с API в Python есть библиотека requests.
Большинство API имеют ограничения на количество запросов. Для их соблюдения нужно добавлять задержки.
Использование прокси и обход блокировок
Прокси помогают обходить блокировки, которые сайты применяют для защиты от парсинга — не всем нравится, когда их контент собирают в базы. Если сайт блокирует ваш IP-адрес из-за частых запросов, использование прокси позволит продолжить работу под другим IP.
В Python для работы с прокси нужно импортировать библиотеки requests и urllib. Достаточно указать адрес прокси в параметрах запроса.
Пример использования прокси с requests:
proxies = {
'http': 'http://user:password@yourproxy.com:port',
'https': 'https://user:password@yourproxy.com:port'
}
response = requests.get('https://example.com', proxies=proxies)
Ваш парсер останется незамеченным, если выполнять подмену User-Agent, ставить задержки между запросами, настроить автоматическое распознавание капчи.
Если сайт предоставляет API, лучше делать запросы через него — это наиболее безопасный и эффективный способ.
Рекомендации по парсингу данных
Структура проекта способствует его поддержке, расширению и повторному использованию. Делите большие парсеры на отдельные компоненты по функциональности — один модуль для авторизации, другой для навигации по страницам, третий для извлечения тегов.
Файлы, полученные при парсинге, также требуют правильной организации хранения и обработки. Выбор формата зависит от объема и структуры данных:
- JSON подходит для иерархических данных и удобен для дальнейшей обработки в Python.
- CSV эффективен для табличных данных и открывается в Excel.
Для больших объемов информации используйте БД — SQLite для небольших проектов, PostgreSQL для масштабных. Создавайте промежуточное хранилище перед финальной записью — это защитит от потери информации при сбоях.
Задержки между запросами — обязательный элемент парсинга. Базовая рекомендация — выдерживайте паузу 1-3 секунды между запросами. Для высоконагруженных сайтов увеличивайте интервал до 5-10 секунд.
Дополнительные советы по созданию парсера:
- Реализуйте систему логирования для отслеживания ошибок и прогресса.
- Обрабатывайте сетевые ошибки, делайте повторные попытки с экспоненциальной выдержкой.
- Используйте прокси, User Agent для распределения нагрузки и маскировки запросов.
- Проверяйте работоспособность парсера перед запуском, так как структура сайтов может меняться.
Парсинг — это автоматический поиск различных паттернов (на основе заранее определенных конструкций) из текстовых источников данных для извлечения специфической информации.
Не смотря на то, что парсинг — широкое понятие, чаще всего под этим термином подразумевают процесс сбора и анализа данных с удаленных веб-ресурсов.
В языке программирования Python программы для парсинга данных со сторонних сайтов могут быть созданы с помощью двух ключевых инструментов:
-
Стандартного пакета HTTP-запросов
-
Внешней библиотеки обработки HTML-разметки
Впрочем, возможности по обработке данных не ограничиваются лишь HTML-документами.
Благодаря множеству внешних библиотек в языке Python можно организовать парсинг документов любой сложности, будь то произвольный текст, популярный язык разметки (например, XML) или редкий язык программирования.
В том случае, если подходящей библиотеки для парсинга не существует, ее можно реализовать вручную на основе тех низкоуровневых методов, которые язык Python предоставляет по умолчанию. Например, на простом поиске вхождений или регулярных выражениях. Хотя, конечно, это требует дополнительных навыков.
В этом руководстве будут рассмотрены способы организации парсеров в языке программирования Python. Речь пойдет об извлечении данных с HTML-страниц на основе заранее указанных тегов и атрибутов.
Все показанные примеры запускались с помощью интерпретатора Python версии 3.10.12 на облачном сервере Timeweb Cloud под управлением операционной системы Ubuntu 22.04. В качестве пакетного менеджера использовался Pip версии 22.0.2.
Структура HTML-документа
Любой документ, написанный на HTML, состоит из тегов двух типов:
-
Открывающий. Указывается внутри символов меньше (
<) и больше (>). Например,<div>.
-
Закрывающий. Указывается в внутри символов меньше (
<) и больше (>) с указанием косой черты (/). Например,</div>.
При этом каждый тег может иметь различные атрибуты, значения которых записываются в кавычках через символ равно. Например, чаще всего используются атрибуты, показывающие принадлежность тега к определенному типу:
-
href. Ссылка на ресурс. Например,
href="https://timeweb.cloud".
-
class. Класс объекта. Например,
class="surface panel panel_closed".
-
id. Идентификатор объекта. Например,
id="menu".
Каждый тег с атрибутами (и без них) является элементом (объектом) так называемого дерева DOM (Document Object Model), которое строится практически любым интерпретатором (процессором) HTML-разметки.
Таким образом выстраивается иерархия элементов, когда вложенные теги являются дочерними по отношению к своим родительским тегам.
Например, в браузере доступ к элементам и их атрибутам выполняется через скрипты JavaScript. А в Python для этого применяются отдельные библиотеки.
Разница лишь в том, что браузер после парсинга HTML-документа не просто строит DOM-дерево, а также выполняет его отображение на мониторе.
Простой HTML-документ может выглядеть так:
<!DOCTYPE html>
<html>
<head>
<title>Это название страницы</title>
</head>
<body>
<h1>Это заголовок</h1>
<p>Это простой текст.</p>
</body>
</html>
Разметка этой страницы построена на тегах с соблюдением иерархии без указания каких-либо атрибутов:
-
html -
head -
title -
body -
h1 -
p
Такой структуры документа уже более чем достаточно для извлечения информации. Считывая данные между открывающим и закрывающим тегами, можно выполнять парсинг.
Однако теги реальных сайтов имеют дополнительные атрибуты, указывающие браузеру как на специфическую функцию конкретного элемента, так и на его особое оформление (которое описывается в отдельных CSS-файлах):
<!DOCTYPE html>
<html>
<body>
<h1 class="h1_bright">Это заголовок</h1>
<p>Это простой текст.</p>
<div class="block" href="https://timeweb.cloud/services/cloud-servers">
<div class="block__title">Облачные сервисы</div>
<div class="block__information">Сервера в облаке</div>
</div>
<div class="block" href="https://timeweb.cloud/services/dedicated-server">
<div class="block__title">Выделенные серверы</div>
<div class="block__information">Инфраструктура в облаке</div>
</div>
<div class="block" href="https://timeweb.cloud/services/apps">
<div class="block__title">Apps</div>
<div class="block__information">Приложения в облаке</div>
</div>
</body>
</html>
Таким образом, помимо явно указанных тегов искомую информацию можно уточнять конкретными атрибутами, вычленяя из дерева DOM только необходимые элементы.
cloud
Устройство парсера данных HTML
Страницы сайтов в сети интернет могут быть двух типов:
-
Статические. В процессе загрузки и просмотра сайта HTML-разметка остается неизменной. Парсинг не требует эмуляции работы браузера.
-
Динамические. В процессе загрузки и просмотра сайта (Single-page application, SPA) HTML-разметка модифицируется с помощью JavaScript. Парсинг требует эмуляции работы браузера.
Парсинг статических сайтов довольно прост — выполняется удаленный запрос, после чего из полученного HTML-документа извлекаются необходимые данные.
Парсинг динамических сайтов требует более сложного подхода. После выполнения удаленного запроса на локальную машину загружается как сам HTML-документ, так и JavaScript-скрипты, управляющие им. Последние, в свою очередь, как правило, автоматически выполняют несколько удаленных запросов, подгружая контент и достраивая HTML-документ уже во время просмотра.
По этой причине парсинг динамических сайтов требует эмуляции работы браузера и действий пользователя на стороне локальной машины. В противном случае необходимые данные просто не будут загружены.
Большинство современных сайтов так или иначе подгружают дополнительный контент с помощью скриптов на JavaScript.
Вариативность технических реализаций современных сайтов настолько велика, что их нельзя назвать ни полностью статическими, ни полностью динамическими.
Как правило, общая информация загружается сразу, а специфическая — уже потом.
Большинство HTML-парсеров заточены под статические страницы. Системы, эмулирующие работу браузера для генерации динамического контента встречаются гораздо реже.
В языке Python библиотеки (пакеты), предназначенные для анализа HTML-разметки, можно разделить на две группы:
-
Низкоуровневые процессоры. Компактные, но синтаксически запутанные пакеты со сложной реализацией, которые выполняют разбор синтаксиса HTML (или XML) и строят иерархическое дерево элементов.
-
Высокоуровневые библиотеки и фреймворки. Обширные, но синтаксически лаконичные пакеты, обладающие широким набором функций для извлечения формализованных данных из сырых HTML-документов. В эту группу входят не только компактные HTML-парсеры, но и полноценные системы сборки. Зачастую такие пакеты в качестве ядра парсинга используют низкоуровневые пакеты (процессоры) из предыдущей группы.
Для Python написано несколько низкоуровневых библиотек:
-
lxml. Низкоуровневый процессор синтаксиса XML, который также используется для анализа HTML. В его основе лежит популярная библиотека
libxml2, написанная на языке C.
-
html5lib. Библиотека анализа синтаксиса HTML, написанная на чистом Python в соответствии с HTML-спецификацией от организации WHATWG (The Web Hypertext Application Technology Working Group), которой следуют все современные браузеры.
Тем не менее, использование высокоуровневых библиотек быстрее и проще — их синтаксис понятнее, а набор функций шире:
-
BeautifulSoup. Простая, но гибкая библиотека для Python, позволяющая парсить документы на HTML и XML путем создания полноценного DOM-дерева элементов с последующим извлечением необходимых данных.
-
Scrapy. Полноценный фреймворк парсинга данных из HTML-страниц, представляющий собой набор автономных «пауков» (веб-краулеров) с заданными инструкциями.
-
Selectolax. Довольно быстрый парсер HTML-страниц, использующий так называемые CSS-селекторы для извлечения информации из тегов.
-
Parsel. Библиотека со специфическим синтаксисом селекторов, написанная на Python, позволяющая извлекать данные из документов на HTML, JSON и XML.
-
requests-html. Удобная библиотека, написанная на Python, которая практически точь-в-точь имитирует браузерные CSS-селекторы языка JavaScript.
В этом руководстве будет рассмотрено несколько подобных высокоуровневых библиотек.
Установка пакетного менеджера pip
Все библиотеки парсинга (впрочем, как и многие другие пакеты) в Python загружаются через стандартный пакетный менеджер pip — его потребуется установить отдельно.
Для начала рекомендуется обновить список доступных репозиториев:
sudo apt updateА уже потом выполнить установку самого pip через пакетный менеджер APT:
sudo apt install python3-pip -yФлаг -y позволит утвердительно ответить на все вопросы консольного терминала, возникающие во время установки.
Корректность установки можно проверить, запросив версию pip:
pip3 --versionПосле этого в консольном терминале появится сообщение с версией пакетного менеджера и адресом его установки:
pip 22.0.2 from /usr/lib/python3/dist-packages/pip (python 3.10)Как видно, в этом руководстве используется pip версии 22.0.2.
Установка пакета HTTP-запросов
Как правило, к интерпретатору Python по умолчанию прилагается стандартный пакет Requests, позволяющий совершать запросы к удаленным серверам. Именно он будет использоваться в примерах из этого руководства.
Однако в некоторых случаях его может не быть. Поэтому рекомендуется вручную установить Requests через пакетный менеджер pip:
pip install requestsЕсли пакет уже присутствует в системе, то в консольном терминале появится такое сообщение:
Requirement already satisfied: requests in /usr/lib/python3/dist-packages (2.25.1)В противном случае Requests будет загружен в список пакетов, доступных для импорта в скриптах Python.
Установка
Установка пакета BeautifulSoup версии 4 выполняется через пакетный менеджер pip:
pip install beautifulsoup4После этого библиотека станет доступна для импорта в скриптах Python. Однако для ее работы требуется дополнительно установить ранее описанные низкоуровневые процессоры HTML.
Поэтому сперва установим lxml:
pip install lxmlА после этого html5lib:
pip install html5libВ дальнейшем в коде приложения Python можно будет указать один из этих процессоров в качестве ядра парсера BeautifulSoup.
Использование
В домашней директории создадим новый файл:
nano bs.pyПосле чего наполним его кодом:
import requests # импортируем библиотеку удаленных запросов
from bs4 import BeautifulSoup # импортируем библиотеку парсинга BeautifulSoup
response = requests.get('https://timeweb.cloud') # выполняем запрос к удаленному серверу Timeweb Cloud
page = BeautifulSoup(response.text, 'html5lib') # парсим ответ удаленного сервера, указывая в качестве процессора парсера библиотеку html5lib
pageTitle = page.find('title') # извлекаем заголовок с тегами <title></title>
print(pageTitle) # выводим заголовок с тегами
print(pageTitle.string) # выводим заголовок без тегов
print("")
pageParagraphs = page.find_all('a') # извлекаем все ссылки с тегами <a></a>
# выводим текст всех найденных элементов
if len(pageParagraphs) >= 3:
# выводим содержимое (без тегов) найденных ссылок
for i in range(3):
print(pageParagraphs[i].string)
print("")
pageItemprop = page.find_all(itemprop='sameAs') # извлекаем все теги, содержащие атрибут itemprop со значением sameAs
# выводим значения атрибута href всех найденных элементов
for item in pageItemprop:
print(item['href'])
print("")
pageMetas = page.find('div', itemprop='address').find_all('meta') # извлекаем все теги meta, размещенные внутри элемента div с атрибутом itemprop, значение которого равно address
# выводим значения атрибута content всех найденных элементов
for meta in pageMetas:
print(meta['content'])
Теперь можно запустить скрипт:
python bs.pyРезультатом его работы станет вот такой консольный вывод:>
<title>Облачная инфраструктура для бизнеса — Timeweb Cloud</title>
Облачная инфраструктура для бизнеса — Timeweb Cloud
О компании
Документация
Бухгалтерам
https://github.com/timeweb-cloud
https://vk.com/timewebru
https://www.youtube.com/channel/UCTSnrzx_YKQOzTR1Y6OxxSQ?sub_confirmation=1
https://habr.com/ru/company/timeweb/profile/
https://vc.ru/u/66957-timeweb-cloud
https://dzen.ru/timewebcloud
https://pikabu.ru/@Timeweb.Cloud
https://tenchat.ru/timewebcloud
Россия
196006
Санкт-Петербург
улица Заставская, дом 22, к.2, лит. А, помещ. 303
Разумеется, вместо html5lib можно указывать lxml:
...
page = BeautifulSoup(response.text, 'lxml')
...Однако лучше всего в качестве процессора использовать библиотеку html5lib. В отличие от lxml, которая заточена исключительно под работу с XML-разметкой, html5lib была разработана с учетом всех современных стандартов HTML5.
Несмотря на то, что библиотека BeautifulSoup имеет лаконичный синтаксис, она не поддерживает эмуляцию браузера, а значит не способна динамически подгружать контент.
Scrapy
Фреймворк Scrapy реализован в более объектно-ориентированном виде. Парсинг сайтов в нем основан на трех базовых сущностях:
-
Пауки (Spiders). Классы, содержащие информацию о нюансах парсинга указанных сайтов: URL-адреса, селекторы (CSS или XPath) элементов и механизм просмотра страниц.
-
Элементы (Items). Переменные для хранения извлеченных данных, представляющие собой более сложную форму словарей Python с особой внутренней структурой.
-
Каналы (Pipelines). Промежуточные обработчики извлеченных данных, способные изменять элементы и взаимодействовать с внешним ПО (например, базами данных).
Установка Scrapy выполняется через пакетный менеджер pip:
pip install scrapyПосле этого необходимо инициализировать проект парсера, тем самым создав отдельную директорию со своей структурой каталогов и конфигурационных файлов:
scrapy startproject parserТеперь можно перейти в только что созданную директорию:
cd parserПроверим содержимое текущего каталога:
lsОн состоит из общего конфигурационного файла и директории с исходниками проекта:
parser scrapy.cfgПереходим к исходникам:
cd parserЕсли проверить ее содержимое:
ls-— то можно увидеть как специальные скрипты Python, каждый из которых выполняет свою функцию, так и отдельный каталог для пауков:
__init__.py items.py middlewares.py pipelines.py settings.py spidersОткроем файл настроек:
nano settings.pyПо умолчанию большая часть параметров закомментированы с помощью символа решетки (#). Для корректной работы парсера часть этих параметров необходимо раскомментировать, не изменяя указанные в файле значения по умолчанию:
-
USER_AGENT -
ROBOTSTXT_OBEY -
CONCURRENT_REQUESTS -
DOWNLOAD_DELAY -
COOKIES_ENABLED
Так или иначе, для каждого конкретного проекта потребуется более точная конфигурация фреймворка. Поэтому список всех параметров, доступных для настройки, можно найти на отдельной странице в официальной документации.
После этого можно сгенерировать нового паука:
scrapy genspider timewebspider timeweb.cloudВ консольном терминале должно появиться сообщение о создании нового паука:
Created spider 'timewebspider' using template 'basic' in module:
parser.spiders.timewebspiderТеперь, если проверить содержимое каталога с пауками:
ls spiders— то в нем можно увидеть пустые исходники нового паука:
__init__.py __pycache__ timewebspider.pyОткроем файл скрипта:
nano spiders/timewebspider.pyИ наполним следующим кодом:
from pathlib import Path # пакет для работы с файлами
import scrapy # пакет фреймворка Scrapy
class TimewebSpider(scrapy.Spider): # класс паука наследуется от класса Spider
name = 'timewebspider' # имя паука
def start_requests(self):
urls = ["https://timeweb.cloud"]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
open("output", "w").close()
someFile = open("output", "a") # создаем новый файл
dataTitle = response.css("title::text").get() # извлекаем заголовок из ответа сервера с помощью CSS-селектора
dataA = response.css("a").getall() # извлекаем все ссылки из ответа сервера с помощью CSS-селектора
someFile.write(dataTitle + "\n\n")
for i in range(3): someFile.write(dataA[i] + "\n")
someFile.close()
Теперь можно запустить созданный паук:
scrapy crawl timewebspiderПосле этого в текущей директории появится файл output:
cat outputЕго содержимое будет следующим:
Облачная инфраструктура для бизнеса — Timeweb Cloud
<a itemprop="url" class="link---GC2"><span itemprop="name">О компании</span></a>
<a itemprop="url" class="link---GC2"><span itemprop="name">Документация</span></a>
<a href="https://timeweb.com/ru/documents/" itemprop="url" target="_blank" class="link---GC2"><span itemprop="name">Бухгалтерам</span></a>
Более подробную информацию об извлечении данных с помощью селекторов (как CSS, так и XPath) можно найти в официальной документации Scrapy.
Заключение
Парсинг данных из удаленных источников в языке Python возможен благодаря двум основным компонентам:
-
Пакет для выполнения удаленных запросов
-
Библиотеки для парсинга данных
Последние могут быть как простыми, пригодными лишь для парсинга статических сайтов, так и более сложными, способными эмулировать работу браузера и, как следствие, парсить динамические сайты.
В языке Python наиболее популярны библиотеки для парсинга статических данных:
-
BeautifulSoup
-
Scrapy
Эти инструменты, подобно функциям в JavaScript (например, getElementsByClassName(), использующая CSS-селекторы), позволяют извлекать данные (атрибуты и текст) из элементов DOM-дерева произвольного HTML-документа.